Summary
This experiment investigates mpi collective tuning. Plackett-Burman screening design to optimize MPI collective communication performance across 6 factors.
The design varies 6 factors: msg size (bytes), ranging from 4096 to 1048576, algorithm, ranging from ring to recursive_doubling, ppn, ranging from 16 to 64, eager limit (bytes), ranging from 4096 to 262144, binding, ranging from core to socket, and coll tuning, ranging from on to off. The goal is to optimize 2 responses: allreduce latency (us) (minimize) and bandwidth (GB/s) (maximize). Fixed conditions held constant across all runs include nodes = 32, mpi impl = openmpi.
A Plackett-Burman screening design was used to efficiently test 6 factors in only 16 runs. This design assumes interactions are negligible and focuses on identifying the most influential main effects.
Key Findings
For allreduce latency, the most influential factors were eager limit (24.8%), coll tuning (23.8%), binding (17.8%). The best observed value was 34.2 (at msg size = 4096, algorithm = ring, ppn = 64).
For bandwidth, the most influential factors were algorithm (25.2%), eager limit (24.2%), msg size (19.4%). The best observed value was 30.14 (at msg size = 1048576, algorithm = ring, ppn = 16).
Recommended Next Steps
- Follow up with a response surface design (CCD or Box-Behnken) on the top 3–4 factors to model curvature and find the true optimum.
- Consider whether any fixed factors should be varied in a future study.
- The screening results can guide factor reduction — drop factors contributing less than 5% and re-run with a smaller, more focused design.
Experimental Setup
Factors
| Factor | Levels | Type | Unit |
|---|
msg_size | 4096, 1048576 | continuous | bytes |
algorithm | ring, recursive_doubling | categorical | |
ppn | 16, 64 | continuous | |
eager_limit | 4096, 262144 | continuous | bytes |
binding | core, socket | categorical | |
coll_tuning | on, off | categorical | |
Fixed: nodes=32, mpi_impl=openmpi
Responses
| Response | Direction | Unit |
|---|
allreduce_latency | ↓ minimize | us |
bandwidth | ↑ maximize | GB/s |
Experimental Matrix
The Plackett-Burman Design produces 16 runs. Each row is one experiment with specific factor settings.
| Run | Block | msg_size | algorithm | ppn | eager_limit | binding | coll_tuning |
|---|
| 1 | 1 | 1048576 | recursive_doubling | 64 | 4096 | core | on |
| 2 | 1 | 4096 | ring | 64 | 262144 | core | on |
| 3 | 1 | 4096 | recursive_doubling | 16 | 262144 | core | off |
| 4 | 1 | 1048576 | recursive_doubling | 64 | 262144 | socket | off |
| 5 | 1 | 4096 | recursive_doubling | 16 | 4096 | socket | on |
| 6 | 1 | 1048576 | ring | 16 | 262144 | socket | on |
| 7 | 1 | 4096 | ring | 64 | 4096 | socket | off |
| 8 | 1 | 1048576 | ring | 16 | 4096 | core | off |
| 9 | 2 | 1048576 | recursive_doubling | 64 | 4096 | core | on |
| 10 | 2 | 1048576 | recursive_doubling | 64 | 262144 | socket | off |
| 11 | 2 | 4096 | recursive_doubling | 16 | 4096 | socket | on |
| 12 | 2 | 4096 | ring | 64 | 4096 | socket | off |
| 13 | 2 | 4096 | ring | 64 | 262144 | core | on |
| 14 | 2 | 4096 | recursive_doubling | 16 | 262144 | core | off |
| 15 | 2 | 1048576 | ring | 16 | 262144 | socket | on |
| 16 | 2 | 1048576 | ring | 16 | 4096 | core | off |
How to Run
$ doe info --config use_cases/07_mpi_collective_tuning/config.json
$ doe generate --config use_cases/07_mpi_collective_tuning/config.json --output results/run.sh --seed 42
$ bash results/run.sh
$ doe analyze --config use_cases/07_mpi_collective_tuning/config.json
$ doe optimize --config use_cases/07_mpi_collective_tuning/config.json
$ doe optimize --config use_cases/07_mpi_collective_tuning/config.json --multi
$ doe report --config use_cases/07_mpi_collective_tuning/config.json --output report.html
Analysis Results
Generated from actual experiment runs.
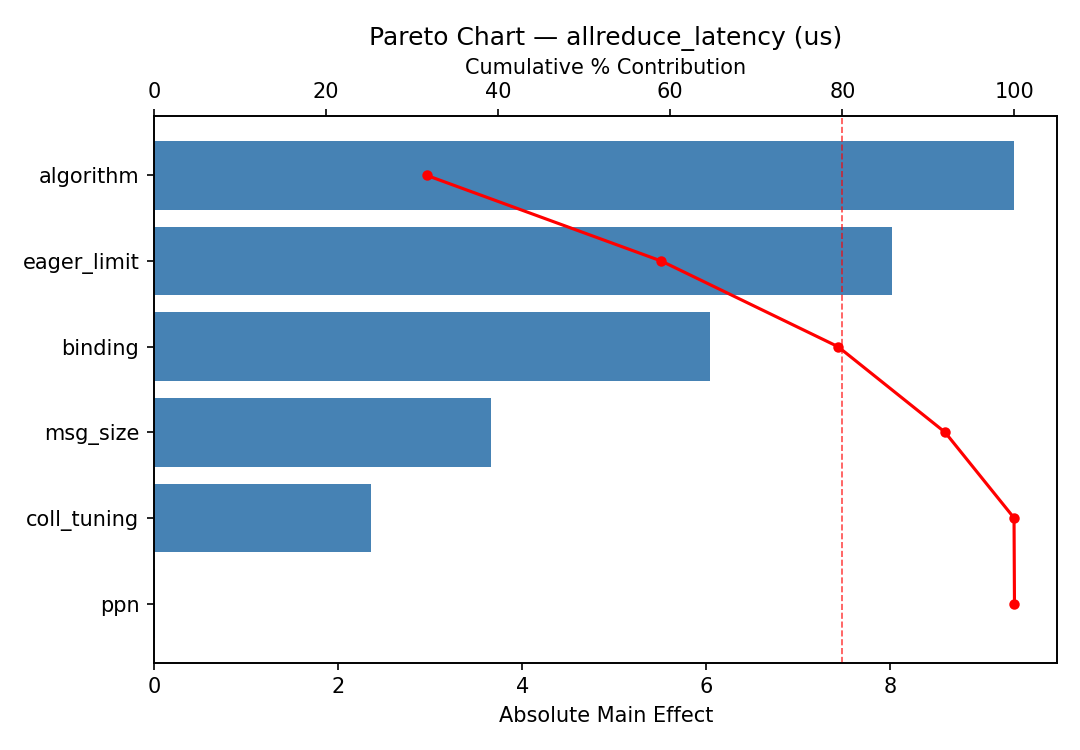
Response: allreduce_latency
Pareto Chart
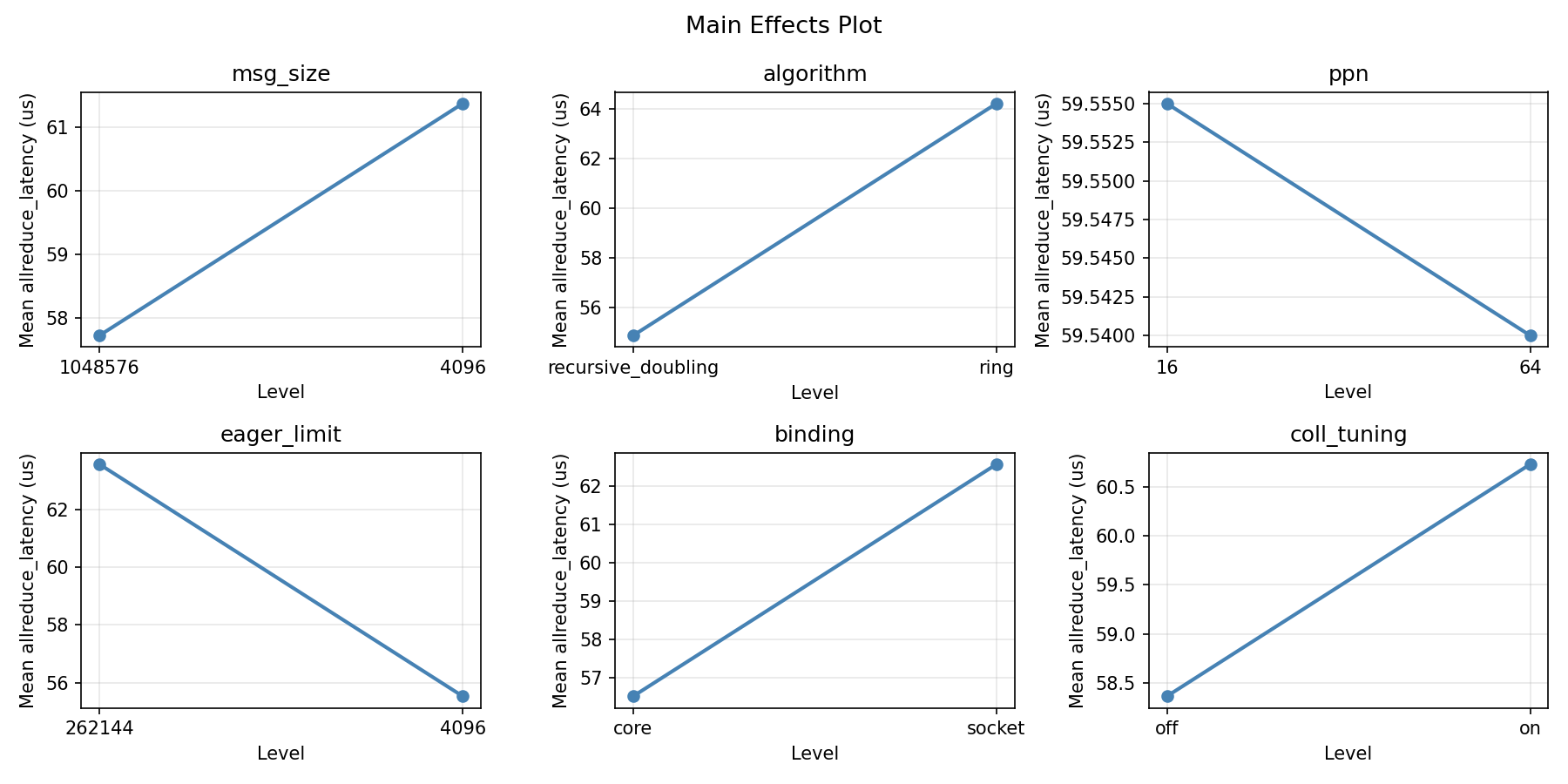
Main Effects Plot
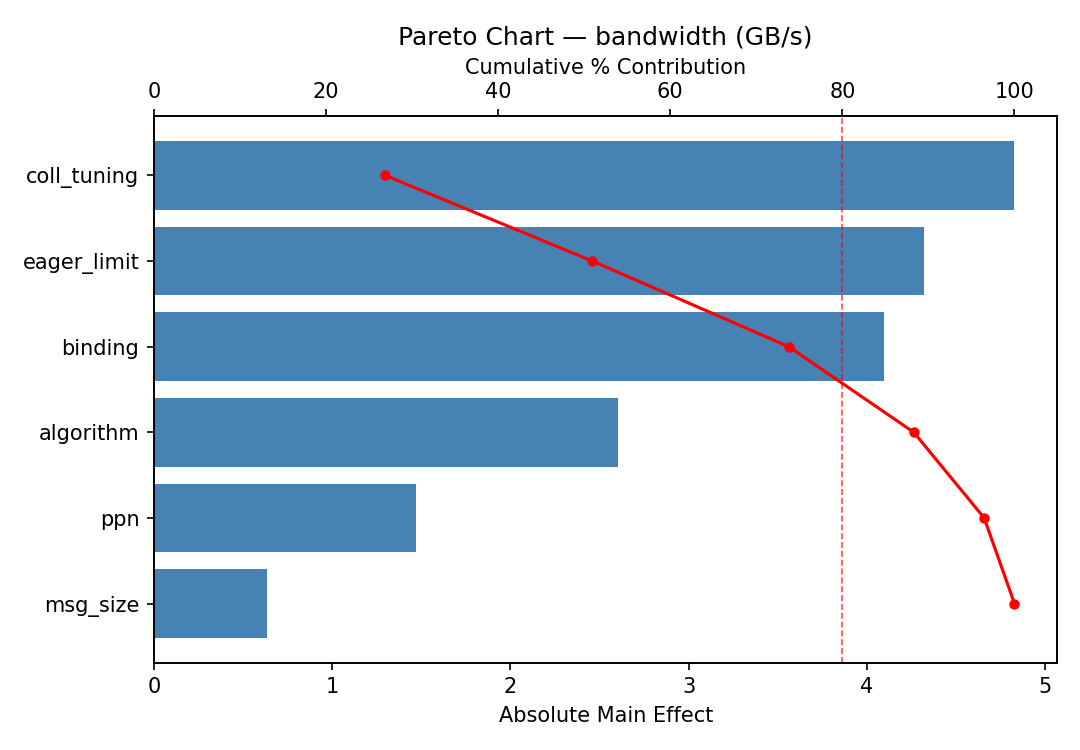
Response: bandwidth
Pareto Chart
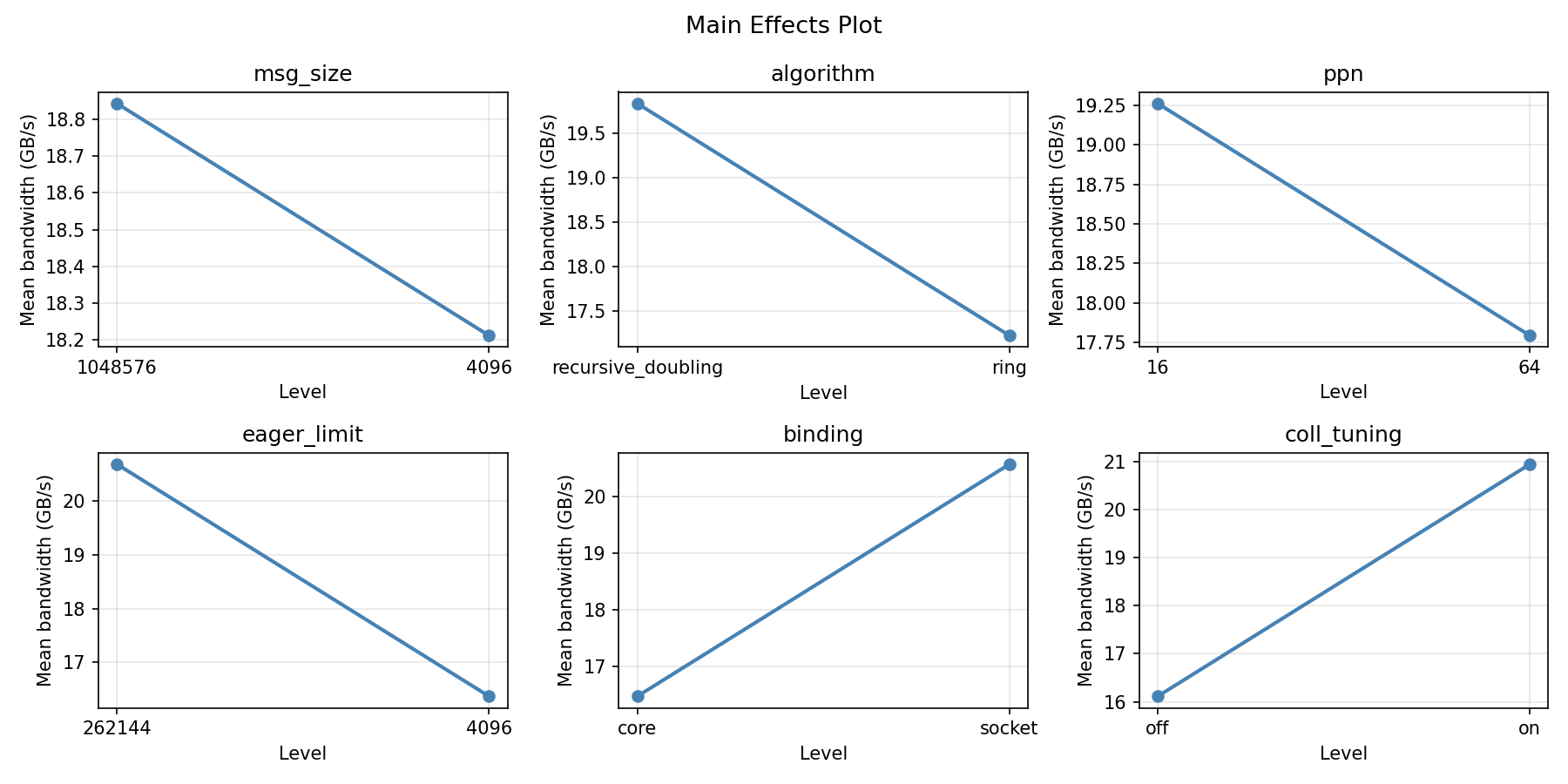
Main Effects Plot
Response Surface Plots
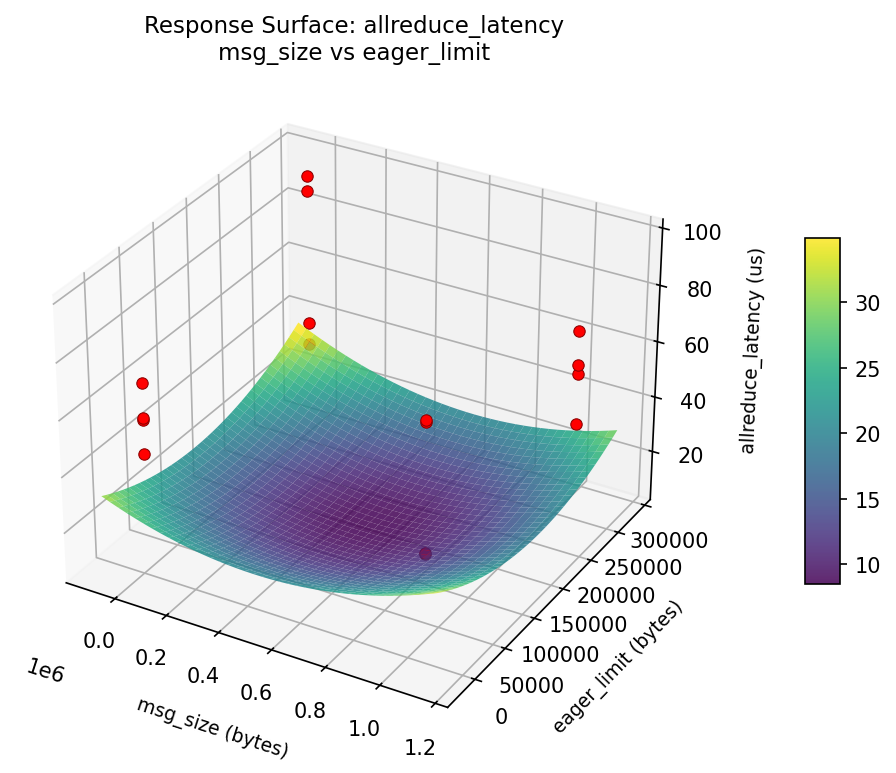
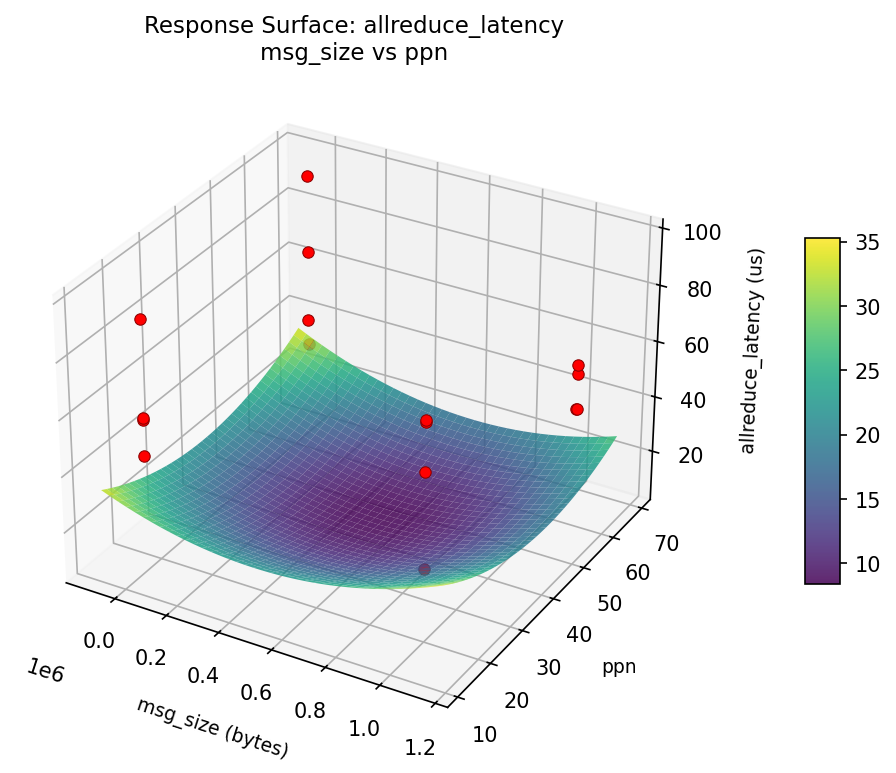
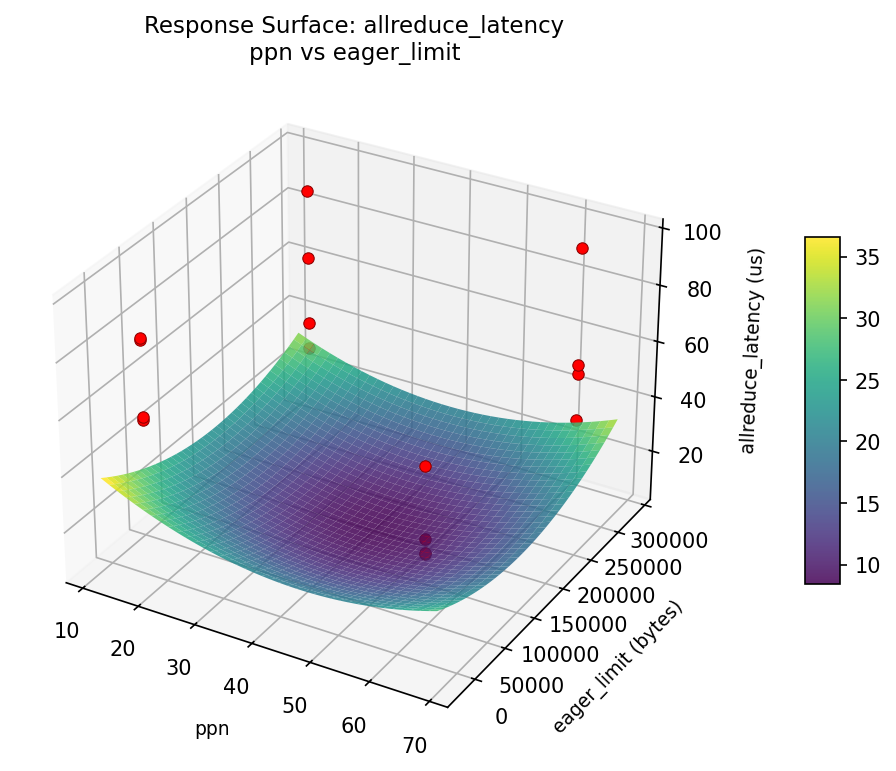
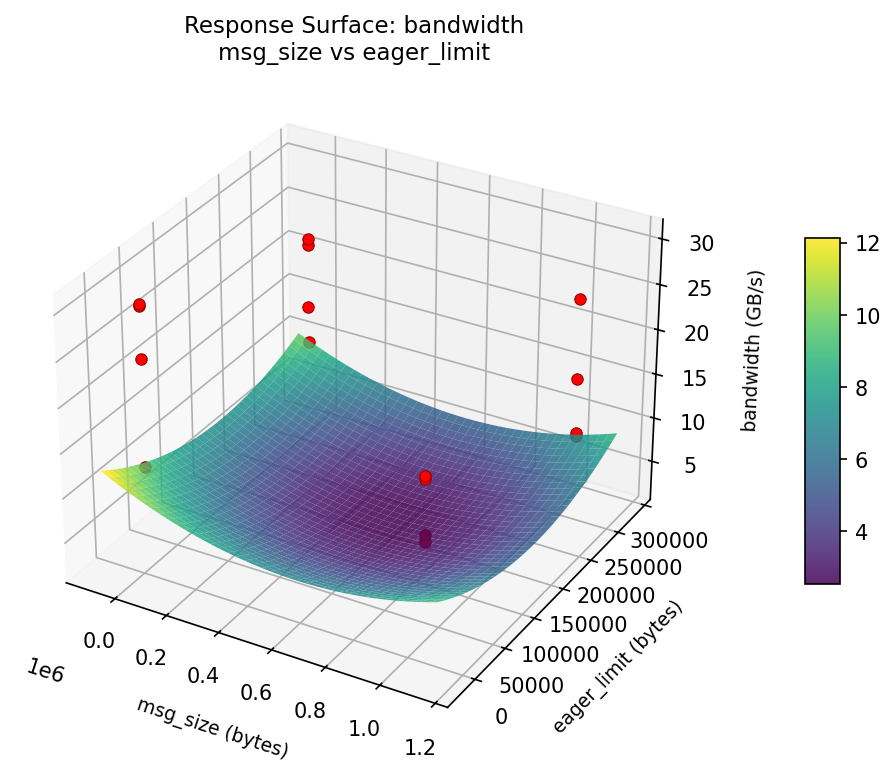
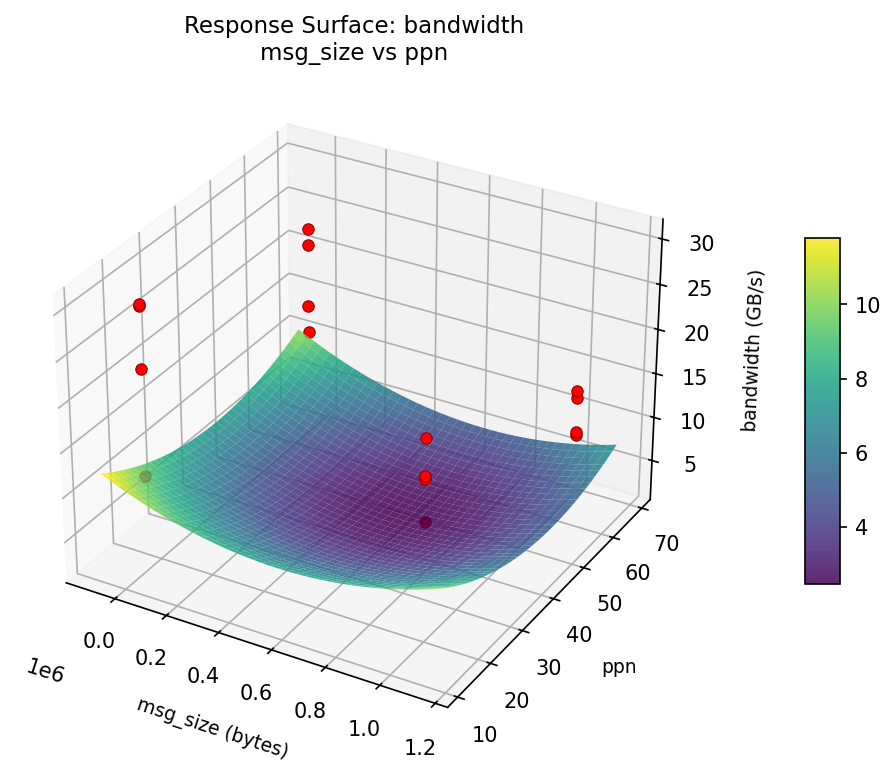
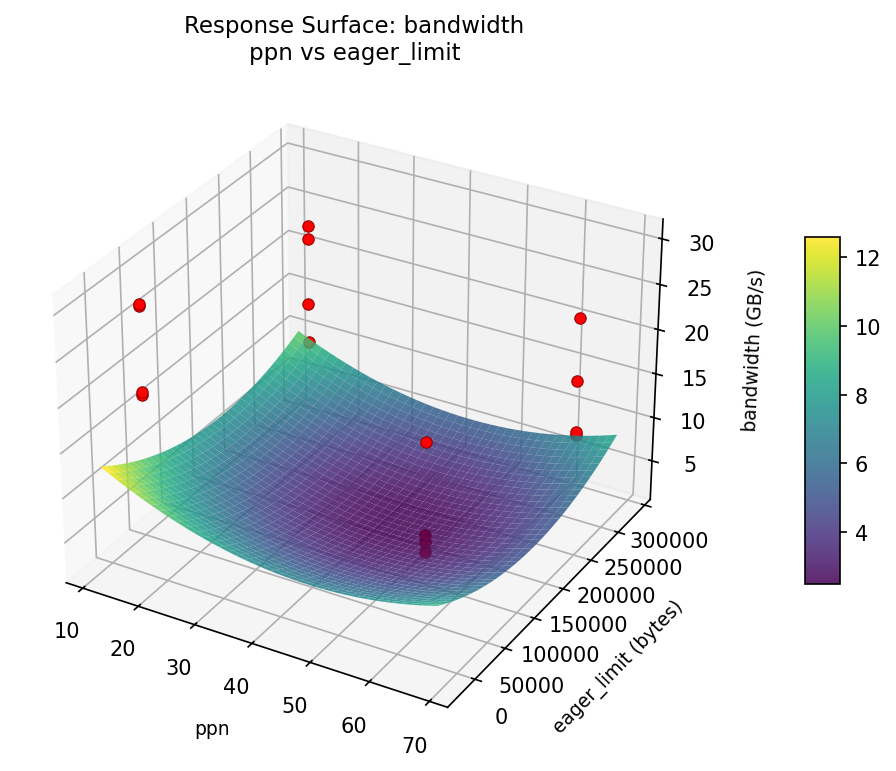
3D surfaces fitted with quadratic RSM. Red dots are observed data points.
📊
How to Read These Surfaces
Each plot shows predicted response (vertical axis) across two factors while other factors are held at center. Red dots are actual experimental observations.
- Flat surface — these two factors have little effect on the response.
- Tilted plane — strong linear effect; moving along one axis consistently changes the response.
- Curved/domed surface — quadratic curvature; there is an optimum somewhere in the middle.
- Saddle shape — significant interaction; the best setting of one factor depends on the other.
- Red dots far from surface — poor model fit in that region; be cautious about predictions there.
allreduce_latency (us) — R² = 0.753, Adj R² = 0.753
Moderate fit — surface shows general trends but some noise remains.
Curvature detected in msg_size, algorithm — look for a peak or valley in the surface.
Strongest linear driver: algorithm (decreases allreduce_latency).
Notable interaction: msg_size × coll_tuning — the effect of one depends on the level of the other. Look for a twisted surface.
bandwidth (GB/s) — R² = 0.299, Adj R² = 0.299
Weak fit — interpret the surface shape with caution.
Curvature detected in msg_size, algorithm — look for a peak or valley in the surface.
Strongest linear driver: algorithm (decreases bandwidth).
Notable interaction: msg_size × coll_tuning — the effect of one depends on the level of the other. Look for a twisted surface.
allreduce: latency msg size vs eager limit
allreduce: latency msg size vs ppn
allreduce: latency ppn vs eager limit
bandwidth: msg size vs eager limit
bandwidth: msg size vs ppn
bandwidth: ppn vs eager limit
Full Analysis Output
=== Main Effects: allreduce_latency ===
Factor Effect Std Error % Contribution
--------------------------------------------------------------
eager_limit -23.7200 5.1709 37.2%
binding 15.3625 5.1709 24.1%
msg_size -13.1775 5.1709 20.7%
ppn -5.9300 5.1709 9.3%
coll_tuning 3.9775 5.1709 6.2%
algorithm -1.6375 5.1709 2.6%
=== Interaction Effects: allreduce_latency ===
Factor A Factor B Interaction % Contribution
------------------------------------------------------------------------
msg_size binding -23.7200 17.8%
algorithm coll_tuning 23.7200 17.8%
msg_size eager_limit 15.3625 11.5%
ppn coll_tuning -15.3625 11.5%
algorithm ppn -13.1775 9.9%
eager_limit binding -13.1775 9.9%
msg_size algorithm -5.9300 4.4%
binding coll_tuning 5.9300 4.4%
algorithm eager_limit -3.9775 3.0%
ppn binding -3.9775 3.0%
msg_size coll_tuning -2.0050 1.5%
algorithm binding 2.0050 1.5%
ppn eager_limit 2.0050 1.5%
msg_size ppn -1.6375 1.2%
eager_limit coll_tuning 1.6375 1.2%
=== Summary Statistics: allreduce_latency ===
msg_size:
Level N Mean Std Min Max
------------------------------------------------------------
1048576 8 66.1363 23.5214 34.2000 96.6600
4096 8 52.9588 16.2556 35.5400 84.3300
algorithm:
Level N Mean Std Min Max
------------------------------------------------------------
recursive_doubling 8 60.3663 21.3574 35.5400 91.5800
ring 8 58.7287 21.4256 34.2000 96.6600
ppn:
Level N Mean Std Min Max
------------------------------------------------------------
16 8 62.5125 24.6412 34.2000 96.6600
64 8 56.5825 17.0131 39.3600 91.5800
eager_limit:
Level N Mean Std Min Max
------------------------------------------------------------
262144 8 71.4075 21.6409 35.5400 96.6600
4096 8 47.6875 11.2646 34.2000 67.4600
binding:
Level N Mean Std Min Max
------------------------------------------------------------
core 8 51.8663 16.2748 34.2000 84.3300
socket 8 67.2288 22.7375 39.6400 96.6600
coll_tuning:
Level N Mean Std Min Max
------------------------------------------------------------
off 8 57.5588 22.0870 34.2000 91.5800
on 8 61.5362 20.4902 39.3600 96.6600
=== Main Effects: bandwidth ===
Factor Effect Std Error % Contribution
--------------------------------------------------------------
eager_limit -4.2275 1.7031 31.1%
ppn -3.5800 1.7031 26.4%
msg_size -2.9300 1.7031 21.6%
coll_tuning -1.0375 1.7031 7.6%
binding 0.9575 1.7031 7.1%
algorithm 0.8400 1.7031 6.2%
=== Interaction Effects: bandwidth ===
Factor A Factor B Interaction % Contribution
------------------------------------------------------------------------
msg_size coll_tuning 5.5025 12.6%
algorithm binding -5.5025 12.6%
ppn eager_limit -5.5025 12.6%
msg_size binding -4.2275 9.7%
algorithm coll_tuning 4.2275 9.7%
msg_size algorithm -3.5800 8.2%
binding coll_tuning 3.5800 8.2%
algorithm ppn -2.9300 6.7%
eager_limit binding -2.9300 6.7%
algorithm eager_limit 1.0375 2.4%
ppn binding 1.0375 2.4%
msg_size eager_limit 0.9575 2.2%
ppn coll_tuning -0.9575 2.2%
msg_size ppn 0.8400 1.9%
eager_limit coll_tuning -0.8400 1.9%
=== Summary Statistics: bandwidth ===
msg_size:
Level N Mean Std Min Max
------------------------------------------------------------
1048576 8 19.9925 6.5195 9.5400 30.1400
4096 8 17.0625 7.2134 9.2100 29.9100
algorithm:
Level N Mean Std Min Max
------------------------------------------------------------
recursive_doubling 8 18.1075 5.6671 9.5400 24.5600
ring 8 18.9475 8.1807 9.2100 30.1400
ppn:
Level N Mean Std Min Max
------------------------------------------------------------
16 8 20.3175 5.5034 13.5000 30.1400
64 8 16.7375 7.8634 9.2100 29.9100
eager_limit:
Level N Mean Std Min Max
------------------------------------------------------------
262144 8 20.6412 6.1679 9.2100 29.9100
4096 8 16.4138 7.1546 9.5400 30.1400
binding:
Level N Mean Std Min Max
------------------------------------------------------------
core 8 18.0488 8.1889 9.2100 30.1400
socket 8 19.0062 5.6445 11.2800 24.5600
coll_tuning:
Level N Mean Std Min Max
------------------------------------------------------------
off 8 19.0463 6.5192 11.2800 30.1400
on 8 18.0087 7.5052 9.2100 29.9100
Optimization Recommendations
=== Optimization: allreduce_latency ===
Direction: minimize
Best observed run: #2
msg_size = 1048576
algorithm = recursive_doubling
ppn = 64
eager_limit = 4096
binding = core
coll_tuning = on
Value: 34.2
RSM Model (linear, R² = 0.27):
Coefficients:
intercept: +59.5475
msg_size: -2.3600
algorithm: -2.4125
ppn: +4.3000
eager_limit: -4.6425
binding: +6.7700
coll_tuning: +3.4600
Predicted optimum:
msg_size = 4096
algorithm = recursive_doubling
ppn = 16
eager_limit = 4096
binding = socket
coll_tuning = on
Predicted value: 74.8925
Factor importance:
1. binding (effect: 13.5, contribution: 28.3%)
2. eager_limit (effect: 9.3, contribution: 19.4%)
3. ppn (effect: 8.6, contribution: 18.0%)
4. coll_tuning (effect: 6.9, contribution: 14.4%)
5. algorithm (effect: -4.8, contribution: 10.1%)
6. msg_size (effect: 4.7, contribution: 9.9%)
=== Optimization: bandwidth ===
Direction: maximize
Best observed run: #15
msg_size = 1048576
algorithm = ring
ppn = 16
eager_limit = 262144
binding = socket
coll_tuning = on
Value: 30.14
RSM Model (linear, R² = 0.21):
Coefficients:
intercept: +18.5275
msg_size: +0.1463
algorithm: +0.9300
ppn: -1.3213
eager_limit: -1.9263
binding: +0.9800
coll_tuning: +1.3487
Predicted optimum:
msg_size = 4096
algorithm = recursive_doubling
ppn = 16
eager_limit = 4096
binding = socket
coll_tuning = on
Predicted value: 23.0275
Factor importance:
1. eager_limit (effect: 3.9, contribution: 29.0%)
2. coll_tuning (effect: 2.7, contribution: 20.3%)
3. ppn (effect: -2.6, contribution: 19.9%)
4. binding (effect: 2.0, contribution: 14.7%)
5. algorithm (effect: 1.9, contribution: 14.0%)
6. msg_size (effect: -0.3, contribution: 2.2%)
Multi-Objective Optimization
When responses compete, Derringer–Suich desirability finds the best compromise.
Each response is scaled to a 0–1 desirability, then combined via a weighted geometric mean.
Overall Desirability
D = 0.8027
Per-Response Desirability
| Response | Weight | Desirability | Predicted | Dir |
|---|
allreduce_latency |
1.0 |
|
56.58 0.6288 56.58 us |
↓ |
bandwidth |
1.5 |
|
29.91 0.9446 29.91 GB/s |
↑ |
Recommended Settings
| Factor | Value |
|---|
msg_size | 1048576 bytes |
algorithm | recursive_doubling |
ppn | 64 |
eager_limit | 4096 bytes |
binding | core |
coll_tuning | on |
Source: from observed run #6
Trade-off Summary
Sacrifice = how much worse than single-objective best.
| Response | Predicted | Best Observed | Sacrifice |
|---|
bandwidth | 29.91 | 30.14 | +0.23 |
Top 3 Runs by Desirability
| Run | D | Factor Settings |
|---|
| #15 | 0.8024 | msg_size=4096, algorithm=recursive_doubling, ppn=16, eager_limit=4096, binding=socket, coll_tuning=on |
| #16 | 0.6033 | msg_size=4096, algorithm=recursive_doubling, ppn=16, eager_limit=262144, binding=core, coll_tuning=off |
Model Quality
| Response | R² | Type |
|---|
bandwidth | 0.3071 | linear |
Full Multi-Objective Output
============================================================
MULTI-OBJECTIVE OPTIMIZATION
Method: Derringer-Suich Desirability Function
============================================================
Overall desirability: D = 0.8027
Response Weight Desirability Predicted Direction
---------------------------------------------------------------------
allreduce_latency 1.0 0.6288 56.58 us ↓
bandwidth 1.5 0.9446 29.91 GB/s ↑
Recommended settings:
msg_size = 1048576 bytes
algorithm = recursive_doubling
ppn = 64
eager_limit = 4096 bytes
binding = core
coll_tuning = on
(from observed run #6)
Trade-off summary:
allreduce_latency: 56.58 (best observed: 34.20, sacrifice: +22.38)
bandwidth: 29.91 (best observed: 30.14, sacrifice: +0.23)
Model quality:
allreduce_latency: R² = 0.2755 (linear)
bandwidth: R² = 0.3071 (linear)
Top 3 observed runs by overall desirability:
1. Run #6 (D=0.8027): msg_size=1048576, algorithm=recursive_doubling, ppn=64, eager_limit=4096, binding=core, coll_tuning=on
2. Run #15 (D=0.8024): msg_size=4096, algorithm=recursive_doubling, ppn=16, eager_limit=4096, binding=socket, coll_tuning=on
3. Run #16 (D=0.6033): msg_size=4096, algorithm=recursive_doubling, ppn=16, eager_limit=262144, binding=core, coll_tuning=off