Summary
This experiment investigates dog training effectiveness. Central composite design to maximize command reliability and minimize training time by tuning session length, reward frequency, and difficulty progression rate.
The design varies 3 factors: session min (min), ranging from 5 to 20, reward ratio pct (%), ranging from 30 to 100, and progression rate (level/wk), ranging from 1 to 5. The goal is to optimize 2 responses: reliability pct (%) (maximize) and sessions to learn (sessions) (minimize). Fixed conditions held constant across all runs include method = positive_reinforcement, breed = labrador.
A Central Composite Design (CCD) was selected to fit a full quadratic response surface model, including curvature and interaction effects. With 3 factors this produces 22 runs including center points and axial (star) points that extend beyond the factorial range.
Quadratic response surface models were fitted to capture potential curvature and factor interactions. The RSM contour plots below visualize how pairs of factors jointly affect each response.
Key Findings
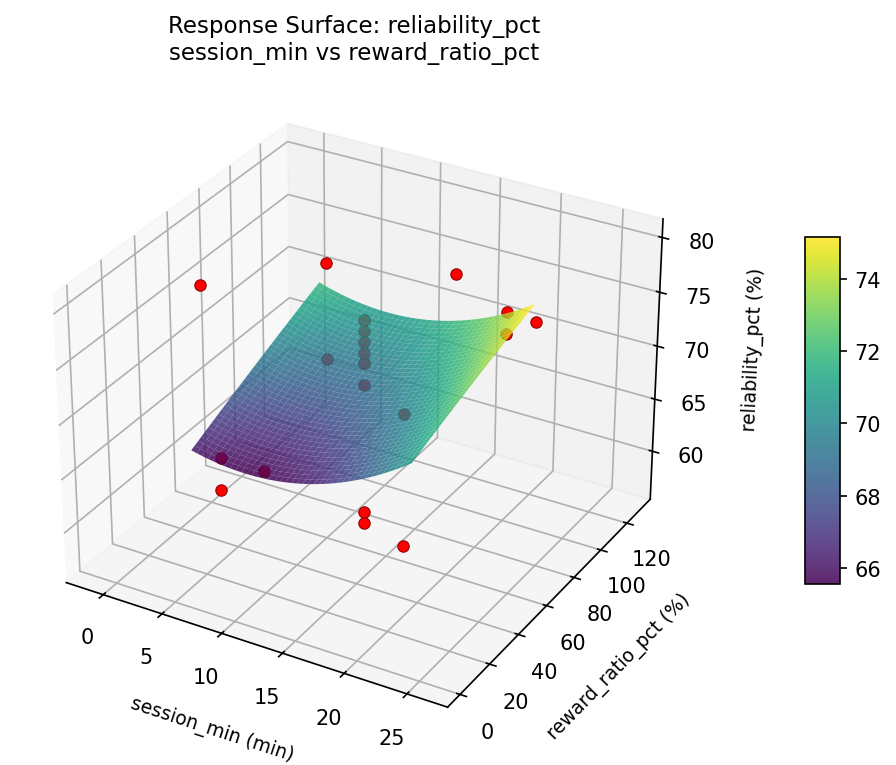
For reliability pct, the most influential factors were progression rate (39.9%), reward ratio pct (32.9%), session min (27.3%). The best observed value was 80.0 (at session min = 12.5, reward ratio pct = 65, progression rate = 6.65148).
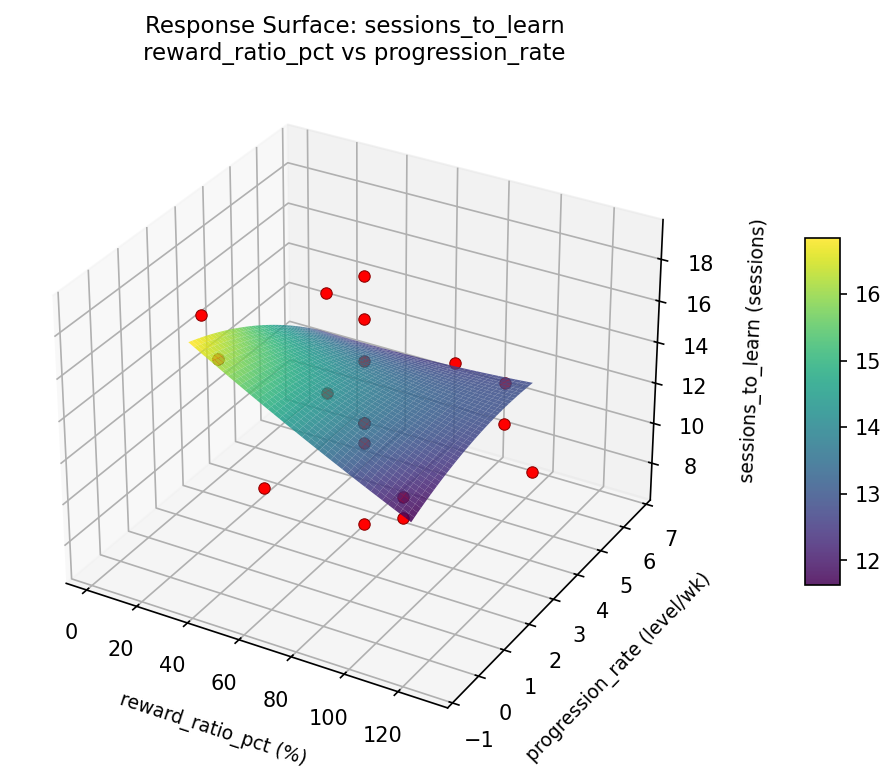
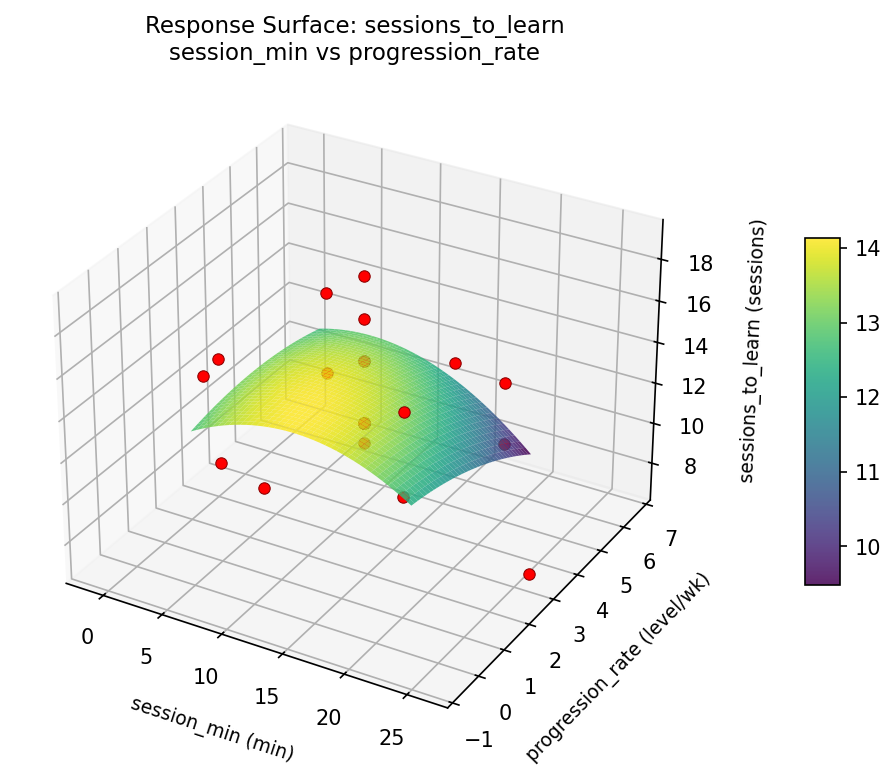
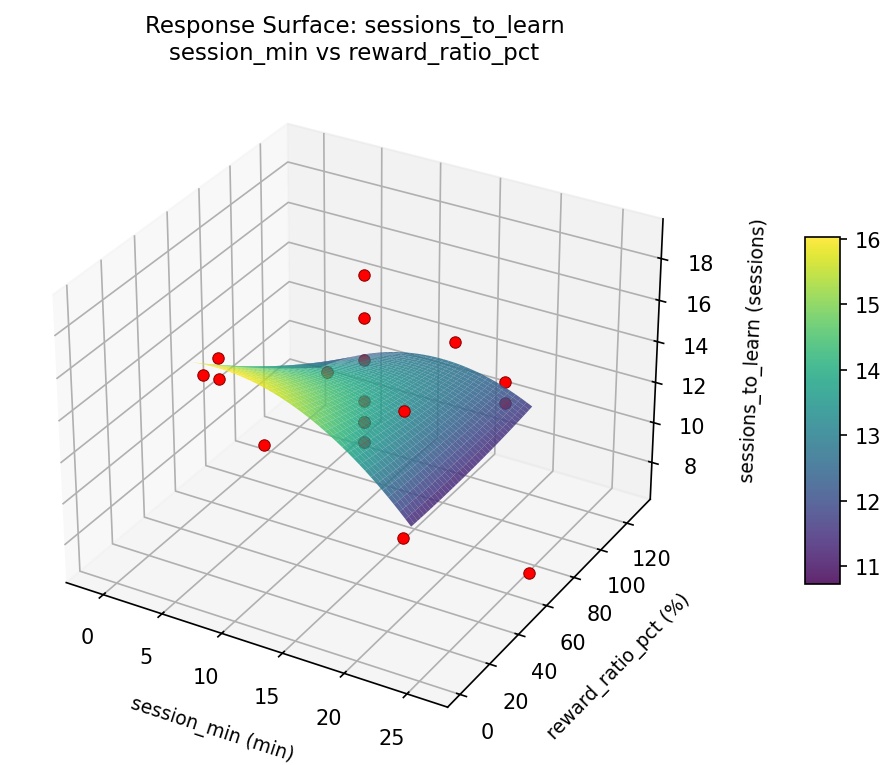
For sessions to learn, the most influential factors were reward ratio pct (38.6%), progression rate (34.1%), session min (27.3%). The best observed value was 7.0 (at session min = 12.5, reward ratio pct = 65, progression rate = 6.65148).
Recommended Next Steps
- Run confirmation experiments at the predicted optimal settings to validate the model.
- Consider whether any fixed factors should be varied in a future study.
Experimental Setup
Factors
| Factor | Low | High | Unit |
|---|
session_min | 5 | 20 | min |
reward_ratio_pct | 30 | 100 | % |
progression_rate | 1 | 5 | level/wk |
Fixed: method = positive_reinforcement, breed = labrador
Responses
| Response | Direction | Unit |
|---|
reliability_pct | ↑ maximize | % |
sessions_to_learn | ↓ minimize | sessions |
Configuration
{
"metadata": {
"name": "Dog Training Effectiveness",
"description": "Central composite design to maximize command reliability and minimize training time by tuning session length, reward frequency, and difficulty progression rate"
},
"factors": [
{
"name": "session_min",
"levels": [
"5",
"20"
],
"type": "continuous",
"unit": "min"
},
{
"name": "reward_ratio_pct",
"levels": [
"30",
"100"
],
"type": "continuous",
"unit": "%"
},
{
"name": "progression_rate",
"levels": [
"1",
"5"
],
"type": "continuous",
"unit": "level/wk"
}
],
"fixed_factors": {
"method": "positive_reinforcement",
"breed": "labrador"
},
"responses": [
{
"name": "reliability_pct",
"optimize": "maximize",
"unit": "%"
},
{
"name": "sessions_to_learn",
"optimize": "minimize",
"unit": "sessions"
}
],
"settings": {
"operation": "central_composite",
"test_script": "use_cases/171_dog_training_protocol/sim.sh"
}
}
Experimental Matrix
The Central Composite Design produces 22 runs. Each row is one experiment with specific factor settings.
| Run | session_min | reward_ratio_pct | progression_rate |
|---|
| 1 | 12.5 | 65 | 3 |
| 2 | 20 | 30 | 5 |
| 3 | 5 | 100 | 1 |
| 4 | 12.5 | 128.901 | 3 |
| 5 | 12.5 | 65 | 3 |
| 6 | -1.19306 | 65 | 3 |
| 7 | 12.5 | 65 | -0.651484 |
| 8 | 12.5 | 65 | 3 |
| 9 | 20 | 100 | 1 |
| 10 | 26.1931 | 65 | 3 |
| 11 | 12.5 | 65 | 3 |
| 12 | 12.5 | 1.09903 | 3 |
| 13 | 12.5 | 65 | 3 |
| 14 | 5 | 30 | 5 |
| 15 | 12.5 | 65 | 3 |
| 16 | 20 | 30 | 1 |
| 17 | 12.5 | 65 | 6.65148 |
| 18 | 20 | 100 | 5 |
| 19 | 12.5 | 65 | 3 |
| 20 | 5 | 30 | 1 |
| 21 | 5 | 100 | 5 |
| 22 | 12.5 | 65 | 3 |
Step-by-Step Workflow
1
Preview the design
$ doe info --config use_cases/171_dog_training_protocol/config.json
2
Generate the runner script
$ doe generate --config use_cases/171_dog_training_protocol/config.json \
--output use_cases/171_dog_training_protocol/results/run.sh --seed 42
3
Execute the experiments
$ bash use_cases/171_dog_training_protocol/results/run.sh
4
Analyze results
$ doe analyze --config use_cases/171_dog_training_protocol/config.json
5
Get optimization recommendations
$ doe optimize --config use_cases/171_dog_training_protocol/config.json
6
Multi-objective optimization
With 2 competing responses, use --multi to find the best compromise via Derringer–Suich desirability.
$ doe optimize --config use_cases/171_dog_training_protocol/config.json --multi
7
Generate the HTML report
$ doe report --config use_cases/171_dog_training_protocol/config.json \
--output use_cases/171_dog_training_protocol/results/report.html
Features Exercised
| Feature | Value |
|---|
| Design type | central_composite |
| Factor types | continuous (all 3) |
| Arg style | double-dash |
| Responses | 2 (reliability_pct ↑, sessions_to_learn ↓) |
| Total runs | 22 |
Analysis Results
Generated from actual experiment runs using the DOE Helper Tool.
Response: reliability_pct
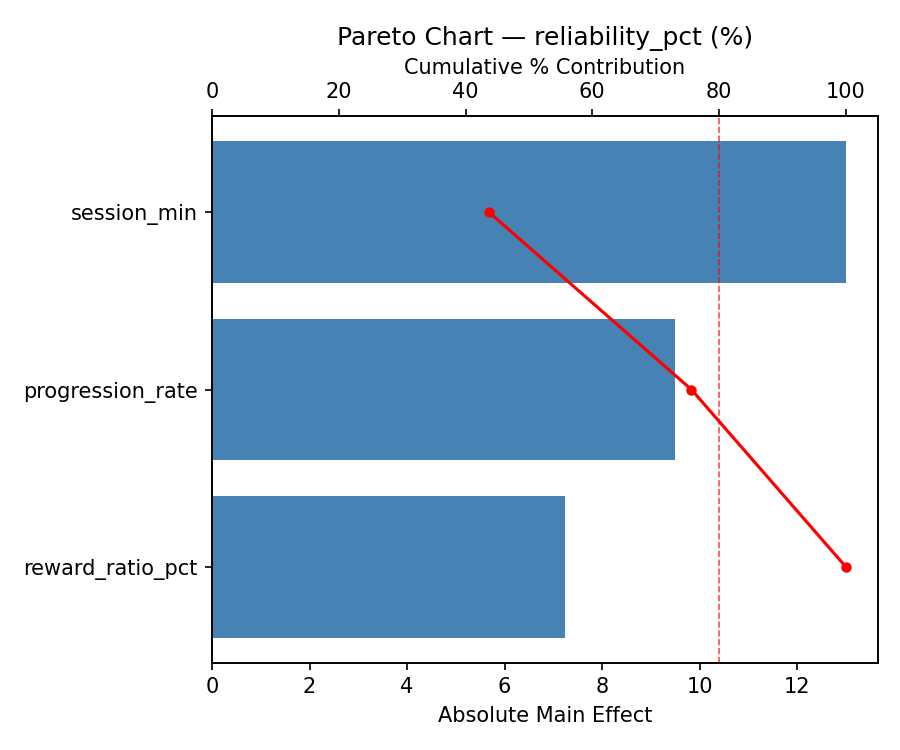
Top factors: progression_rate (39.9%), reward_ratio_pct (32.9%), session_min (27.3%).
ANOVA
| Source | DF | SS | MS | F | p-value |
|---|
| Source | DF | SS | MS | F | p-value |
| session_min | 4 | 207.3182 | 51.8295 | 4.600 | 0.0268 |
| reward_ratio_pct | 4 | 240.6515 | 60.1629 | 5.339 | 0.0175 |
| progression_rate | 4 | 479.6515 | 119.9129 | 10.642 | 0.0018 |
| Lack | of | Fit | 2 | 0.0000 | 0.0000 |
| Pure | Error | 7 | 78.8750 | | |
| Error | 9 | 0.0000 | 11.2679 | | |
| Total | 21 | 813.3182 | 38.7294 | | |
Pareto Chart
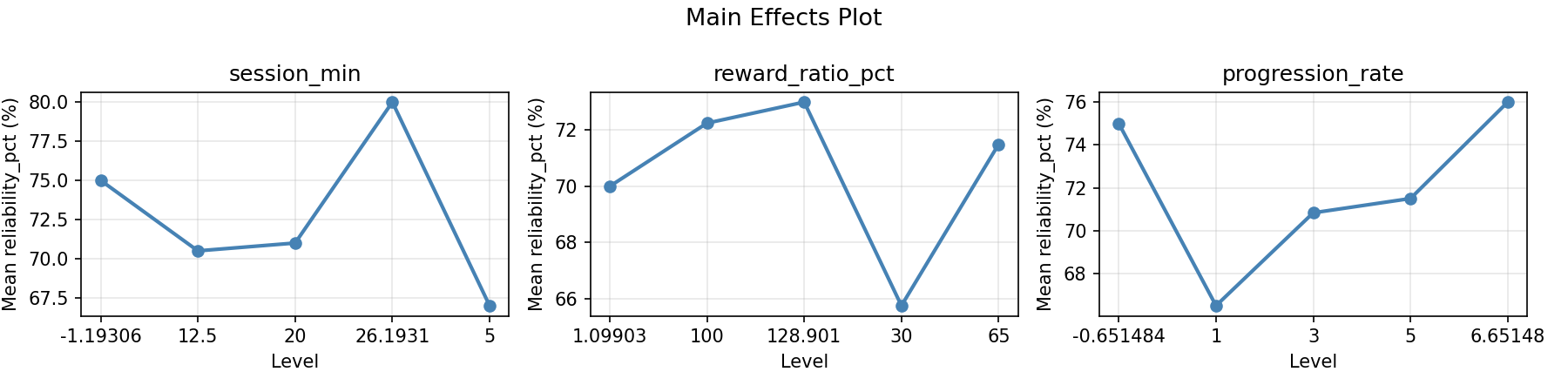
Main Effects Plot
Normal Probability Plot of Effects
Half-Normal Plot of Effects
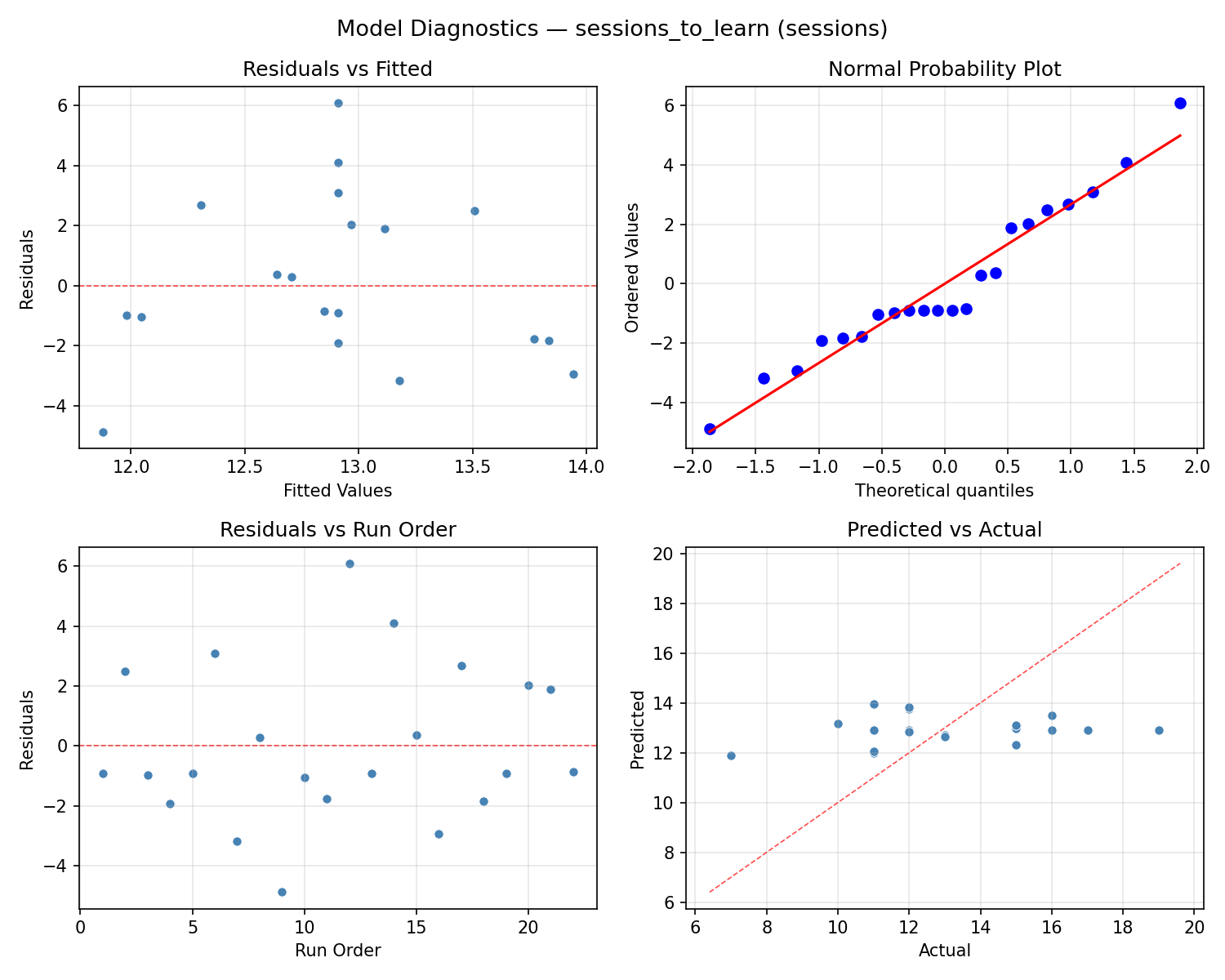
Model Diagnostics
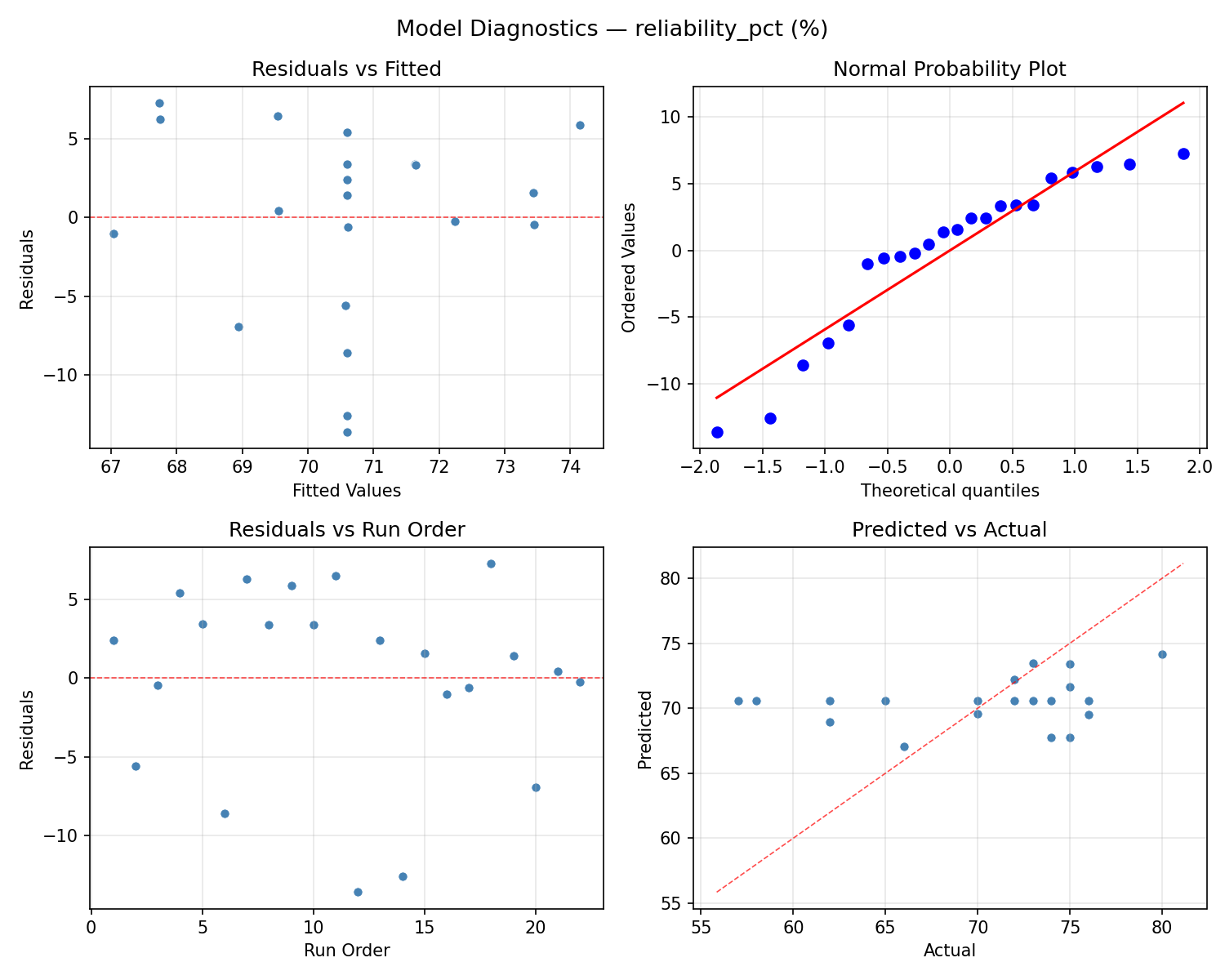
Response: sessions_to_learn
Top factors: reward_ratio_pct (38.6%), progression_rate (34.1%), session_min (27.3%).
ANOVA
| Source | DF | SS | MS | F | p-value |
|---|
| Source | DF | SS | MS | F | p-value |
| session_min | 4 | 16.4015 | 4.1004 | 1.025 | 0.4447 |
| reward_ratio_pct | 4 | 30.4015 | 7.6004 | 1.900 | 0.1947 |
| progression_rate | 4 | 35.0682 | 8.7670 | 2.192 | 0.1509 |
| Lack | of | Fit | 2 | 39.9470 | 19.9735 |
| Pure | Error | 7 | 28.0000 | | |
| Error | 9 | 67.9470 | 4.0000 | | |
| Total | 21 | 149.8182 | 7.1342 | | |
Pareto Chart
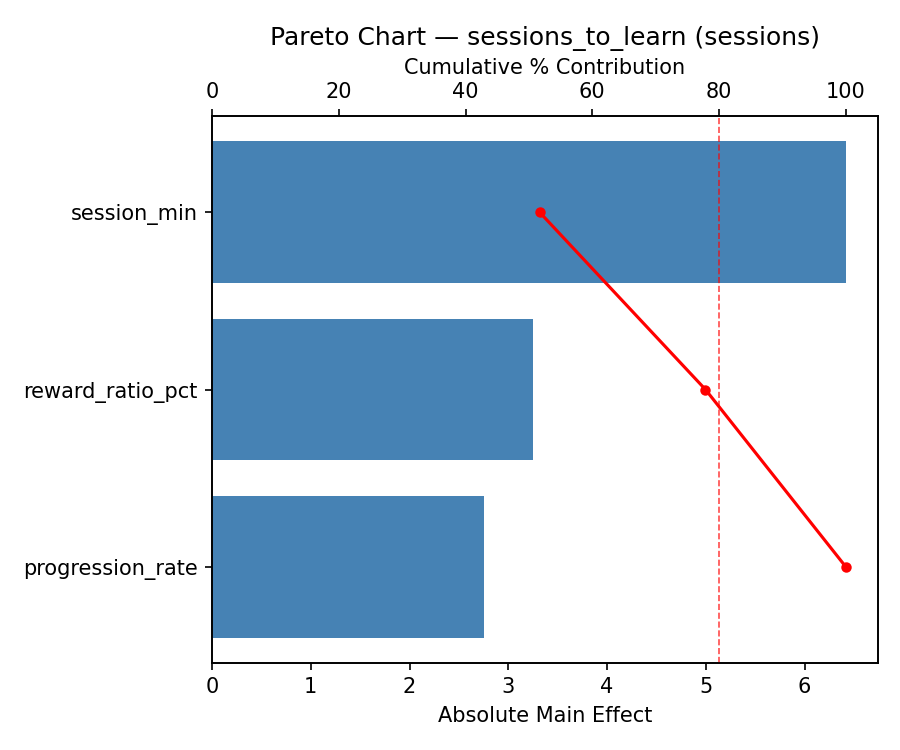
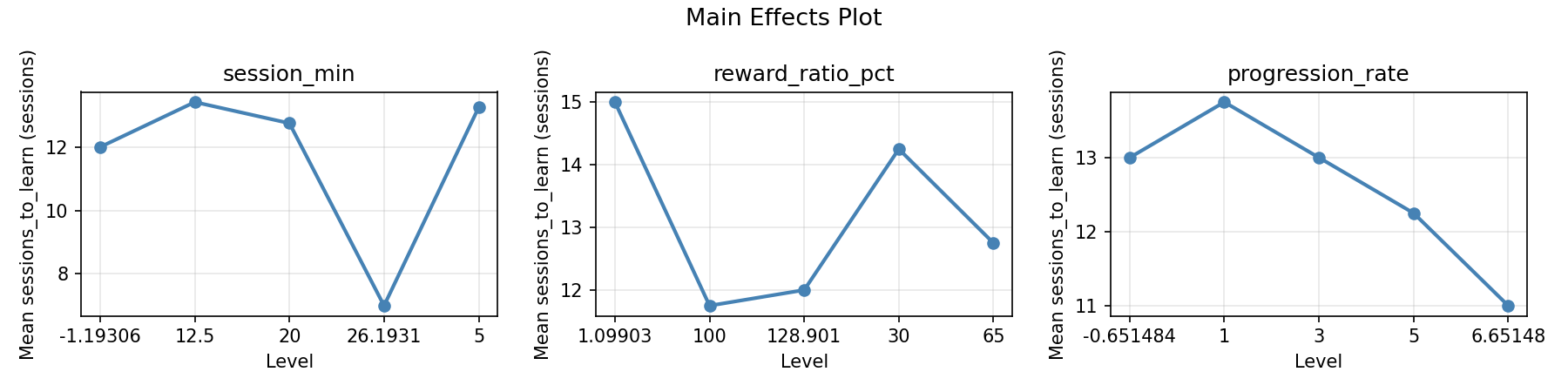
Main Effects Plot
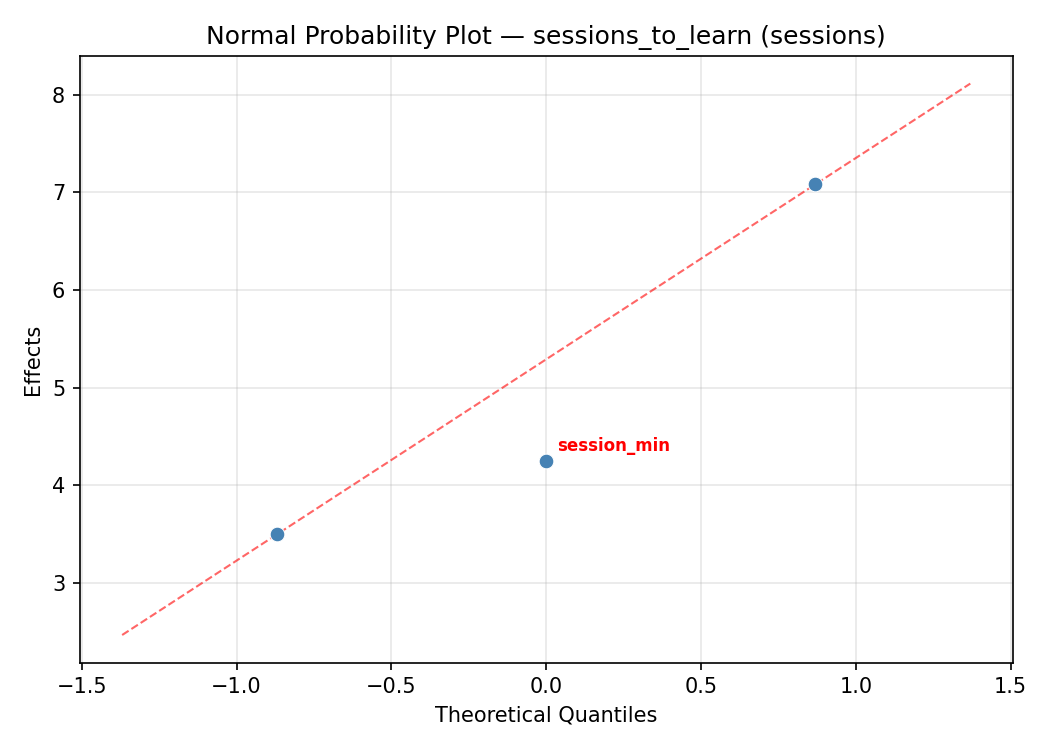
Normal Probability Plot of Effects
Half-Normal Plot of Effects
Model Diagnostics
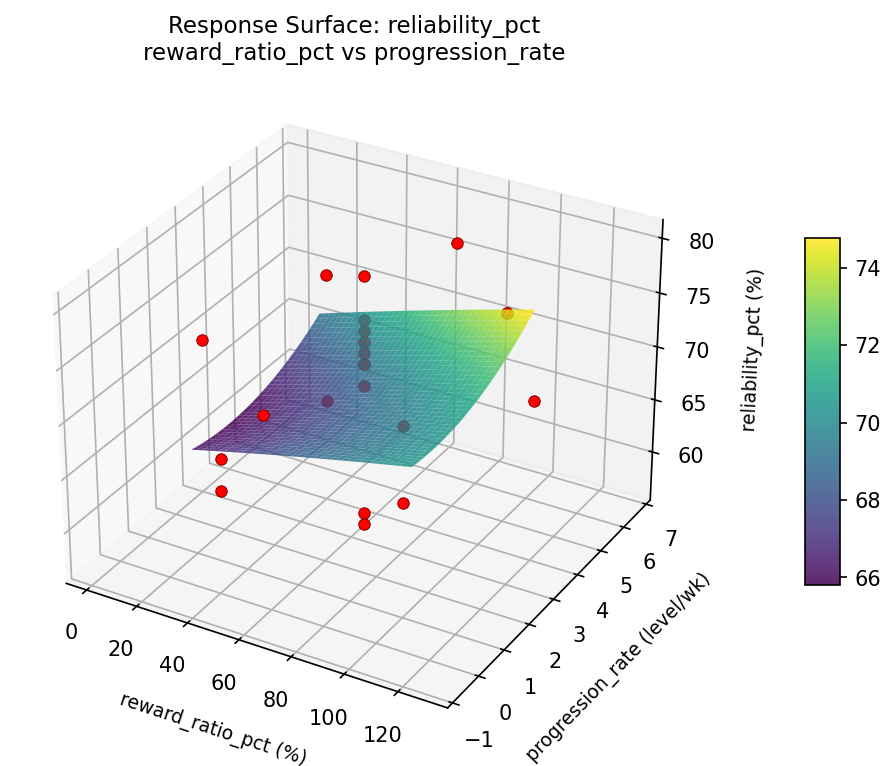
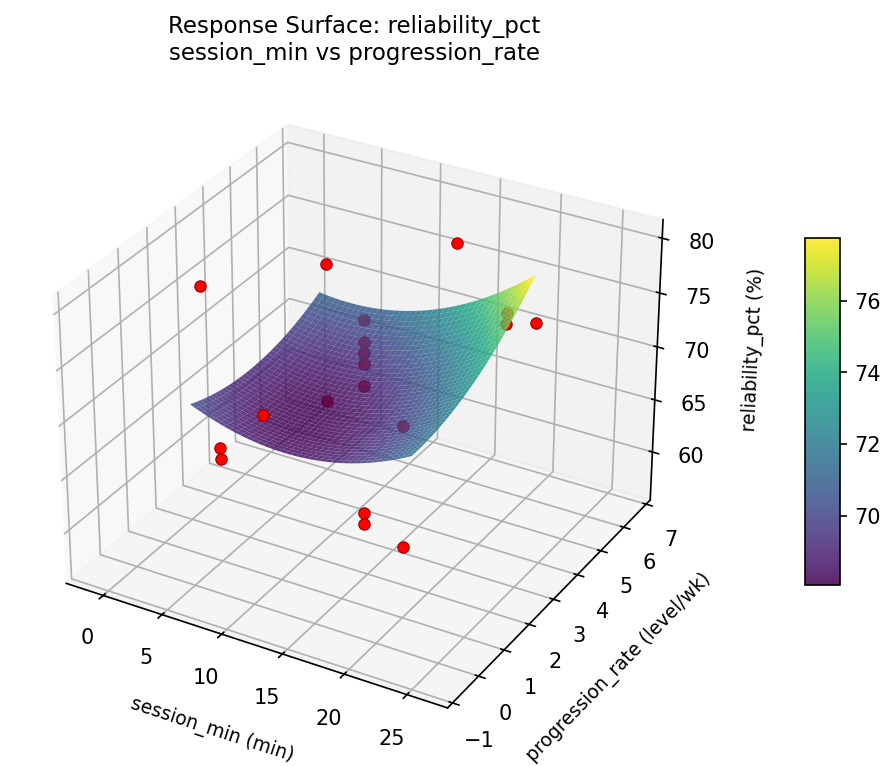
Response Surface Plots
3D surfaces fitted with quadratic RSM. Red dots are observed data points.
reliability pct reward ratio pct vs progression rate
reliability pct session min vs progression rate
reliability pct session min vs reward ratio pct
sessions to learn reward ratio pct vs progression rate
sessions to learn session min vs progression rate
sessions to learn session min vs reward ratio pct
Multi-Objective Optimization
When responses compete, Derringer–Suich desirability finds the best compromise.
Each response is scaled to a 0–1 desirability, then combined via a weighted geometric mean.
Overall Desirability
D = 0.9545
Per-Response Desirability
| Response | Weight | Desirability | Predicted | Dir |
|---|
reliability_pct |
1.5 |
|
80.00 0.9545 80.00 % |
↑ |
sessions_to_learn |
1.0 |
|
7.00 0.9545 7.00 sessions |
↓ |
Recommended Settings
| Factor | Value |
|---|
session_min | 12.5 min |
reward_ratio_pct | 65 % |
progression_rate | 6.65148 level/wk |
Source: from observed run #9
Trade-off Summary
Sacrifice = how much worse than single-objective best.
| Response | Predicted | Best Observed | Sacrifice |
|---|
sessions_to_learn | 7.00 | 7.00 | +0.00 |
Top 3 Runs by Desirability
| Run | D | Factor Settings |
|---|
| #4 | 0.7350 | session_min=12.5, reward_ratio_pct=65, progression_rate=3 |
| #7 | 0.7213 | session_min=12.5, reward_ratio_pct=1.09903, progression_rate=3 |
Model Quality
| Response | R² | Type |
|---|
sessions_to_learn | 0.3560 | linear |
Full Multi-Objective Output
============================================================
MULTI-OBJECTIVE OPTIMIZATION
Method: Derringer-Suich Desirability Function
============================================================
Overall desirability: D = 0.9545
Response Weight Desirability Predicted Direction
---------------------------------------------------------------------
reliability_pct 1.5 0.9545 80.00 % ↑
sessions_to_learn 1.0 0.9545 7.00 sessions ↓
Recommended settings:
session_min = 12.5 min
reward_ratio_pct = 65 %
progression_rate = 6.65148 level/wk
(from observed run #9)
Trade-off summary:
reliability_pct: 80.00 (best observed: 80.00, sacrifice: +0.00)
sessions_to_learn: 7.00 (best observed: 7.00, sacrifice: +0.00)
Model quality:
reliability_pct: R² = 0.1362 (linear)
sessions_to_learn: R² = 0.3560 (linear)
Top 3 observed runs by overall desirability:
1. Run #9 (D=0.9545): session_min=12.5, reward_ratio_pct=65, progression_rate=6.65148
2. Run #4 (D=0.7350): session_min=12.5, reward_ratio_pct=65, progression_rate=3
3. Run #7 (D=0.7213): session_min=12.5, reward_ratio_pct=1.09903, progression_rate=3
Full Analysis Output
=== Main Effects: reliability_pct ===
Factor Effect Std Error % Contribution
--------------------------------------------------------------
progression_rate 14.2500 1.3268 39.9%
reward_ratio_pct 11.7500 1.3268 32.9%
session_min 9.7500 1.3268 27.3%
=== ANOVA Table: reliability_pct ===
Source DF SS MS F p-value
-----------------------------------------------------------------------------
session_min 4 207.3182 51.8295 4.600 0.0268
reward_ratio_pct 4 240.6515 60.1629 5.339 0.0175
progression_rate 4 479.6515 119.9129 10.642 0.0018
Lack of Fit 2 0.0000 0.0000 0.000 1.0000
Pure Error 7 78.8750 11.2679
Error 9 0.0000 11.2679
Total 21 813.3182 38.7294
=== Summary Statistics: reliability_pct ===
session_min:
Level N Mean Std Min Max
------------------------------------------------------------
-1.19306 1 70.0000 0.0000 70.0000 70.0000
12.5 12 72.7500 2.9886 65.0000 76.0000
20 4 68.5000 8.1854 58.0000 75.0000
26.1931 1 75.0000 0.0000 75.0000 75.0000
5 4 65.2500 10.1119 57.0000 80.0000
reward_ratio_pct:
Level N Mean Std Min Max
------------------------------------------------------------
1.09903 1 76.0000 0.0000 76.0000 76.0000
100 4 64.2500 7.4106 58.0000 75.0000
128.901 1 73.0000 0.0000 73.0000 73.0000
30 4 69.5000 10.1489 57.0000 80.0000
65 12 72.4167 2.9987 65.0000 76.0000
progression_rate:
Level N Mean Std Min Max
------------------------------------------------------------
-0.651484 1 72.0000 0.0000 72.0000 72.0000
1 4 60.7500 4.1130 57.0000 66.0000
3 12 72.5833 3.0883 65.0000 76.0000
5 4 73.0000 7.7028 62.0000 80.0000
6.65148 1 75.0000 0.0000 75.0000 75.0000
=== Main Effects: sessions_to_learn ===
Factor Effect Std Error % Contribution
--------------------------------------------------------------
reward_ratio_pct 4.2500 0.5695 38.6%
progression_rate 3.7500 0.5695 34.1%
session_min 3.0000 0.5695 27.3%
=== ANOVA Table: sessions_to_learn ===
Source DF SS MS F p-value
-----------------------------------------------------------------------------
session_min 4 16.4015 4.1004 1.025 0.4447
reward_ratio_pct 4 30.4015 7.6004 1.900 0.1947
progression_rate 4 35.0682 8.7670 2.192 0.1509
Lack of Fit 2 39.9470 19.9735 4.993 0.0449
Pure Error 7 28.0000 4.0000
Error 9 67.9470 4.0000
Total 21 149.8182 7.1342
=== Summary Statistics: sessions_to_learn ===
session_min:
Level N Mean Std Min Max
------------------------------------------------------------
-1.19306 1 15.0000 0.0000 15.0000 15.0000
12.5 12 12.3333 1.6697 10.0000 16.0000
20 4 13.0000 2.8284 11.0000 17.0000
26.1931 1 12.0000 0.0000 12.0000 12.0000
5 4 14.2500 5.1235 7.0000 19.0000
reward_ratio_pct:
Level N Mean Std Min Max
------------------------------------------------------------
1.09903 1 11.0000 0.0000 11.0000 11.0000
100 4 15.2500 1.7078 13.0000 17.0000
128.901 1 12.0000 0.0000 12.0000 12.0000
30 4 12.0000 5.0332 7.0000 19.0000
65 12 12.6667 1.7753 10.0000 16.0000
progression_rate:
Level N Mean Std Min Max
------------------------------------------------------------
-0.651484 1 12.0000 0.0000 12.0000 12.0000
1 4 15.5000 3.4157 11.0000 19.0000
3 12 12.5000 1.8340 10.0000 16.0000
5 4 11.7500 3.7749 7.0000 16.0000
6.65148 1 13.0000 0.0000 13.0000 13.0000
Optimization Recommendations
=== Optimization: reliability_pct ===
Direction: maximize
Best observed run: #9
session_min = 12.5
reward_ratio_pct = 65
progression_rate = 6.65148
Value: 80.0
RSM Model (linear, R² = 0.0911, Adj R² = -0.0604):
Coefficients:
intercept +70.5909
session_min -0.7500
reward_ratio_pct +2.0599
progression_rate +0.4948
RSM Model (quadratic, R² = 0.4646, Adj R² = 0.0630):
Coefficients:
intercept +71.1567
session_min -0.7500
reward_ratio_pct +2.0599
progression_rate +0.4948
session_min*reward_ratio_pct -4.6250
session_min*progression_rate +0.8750
reward_ratio_pct*progression_rate +0.3750
session_min^2 +0.5171
reward_ratio_pct^2 -2.1829
progression_rate^2 +0.8171
Curvature analysis:
reward_ratio_pct coef=-2.1829 concave (has a maximum)
progression_rate coef=+0.8171 convex (has a minimum)
session_min coef=+0.5171 convex (has a minimum)
Notable interactions:
session_min*reward_ratio_pct coef=-4.6250 (antagonistic)
session_min*progression_rate coef=+0.8750 (synergistic)
reward_ratio_pct*progression_rate coef=+0.3750 (synergistic)
Predicted optimum (from quadratic model, at observed points):
session_min = 5
reward_ratio_pct = 100
progression_rate = 1
Predicted value: 77.7481
Surface optimum (via L-BFGS-B, quadratic model):
session_min = 5
reward_ratio_pct = 100
progression_rate = 1
Predicted value: 77.7481
Model quality: Weak fit — consider adding center points or using a different design.
Factor importance:
1. reward_ratio_pct (effect: 16.0, contribution: 47.1%)
2. progression_rate (effect: 12.0, contribution: 35.3%)
3. session_min (effect: 6.0, contribution: 17.6%)
=== Optimization: sessions_to_learn ===
Direction: minimize
Best observed run: #9
session_min = 12.5
reward_ratio_pct = 65
progression_rate = 6.65148
Value: 7.0
RSM Model (linear, R² = 0.1755, Adj R² = 0.0381):
Coefficients:
intercept +12.9091
session_min +0.2490
reward_ratio_pct -0.9959
progression_rate -0.8595
RSM Model (quadratic, R² = 0.5046, Adj R² = 0.1331):
Coefficients:
intercept +12.5670
session_min +0.2490
reward_ratio_pct -0.9959
progression_rate -0.8595
session_min*reward_ratio_pct +1.7500
session_min*progression_rate -0.5000
reward_ratio_pct*progression_rate -0.0000
session_min^2 -0.2289
reward_ratio_pct^2 +0.9711
progression_rate^2 -0.2289
Curvature analysis:
reward_ratio_pct coef=+0.9711 convex (has a minimum)
session_min coef=-0.2289 concave (has a maximum)
progression_rate coef=-0.2289 concave (has a maximum)
Notable interactions:
session_min*reward_ratio_pct coef=+1.7500 (synergistic)
session_min*progression_rate coef=-0.5000 (antagonistic)
Predicted optimum (from quadratic model, at observed points):
session_min = 12.5
reward_ratio_pct = 1.09903
progression_rate = 3
Predicted value: 17.6220
Surface optimum (via L-BFGS-B, quadratic model):
session_min = 5
reward_ratio_pct = 100
progression_rate = 5
Predicted value: 9.7258
Model quality: Moderate fit — use predictions directionally, not precisely.
Factor importance:
1. reward_ratio_pct (effect: 8.0, contribution: 40.5%)
2. progression_rate (effect: 8.0, contribution: 40.5%)
3. session_min (effect: 3.8, contribution: 19.0%)