Summary
This experiment investigates secrets vault performance. Box-Behnken design to optimize vault seal wrap threads, cache size, and lease TTL for latency and throughput.
The design varies 3 factors: seal wrap threads (threads), ranging from 1 to 8, cache size mb (MB), ranging from 64 to 512, and lease ttl sec (sec), ranging from 30 to 600. The goal is to optimize 2 responses: read latency ms (ms) (minimize) and throughput ops (ops/s) (maximize). Fixed conditions held constant across all runs include vault backend = consul, seal type = awskms.
A Box-Behnken design was chosen because it efficiently fits quadratic models with 3 continuous factors while avoiding extreme corner combinations — requiring only 15 runs instead of the 8 needed for a full factorial at two levels.
Quadratic response surface models were fitted to capture potential curvature and factor interactions. The RSM contour plots below visualize how pairs of factors jointly affect each response.
Key Findings
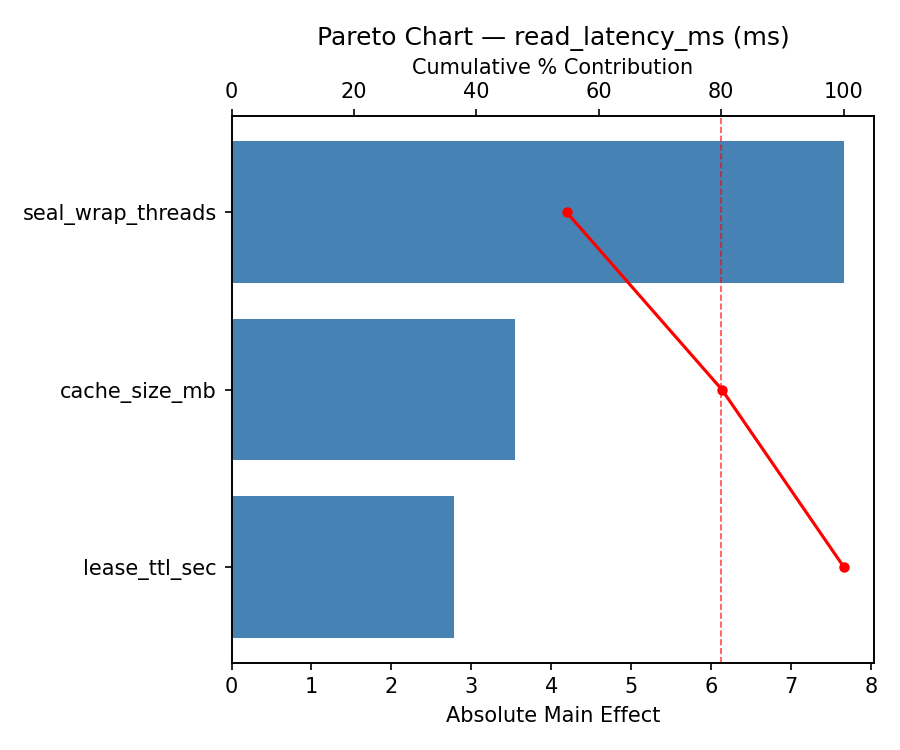
For read latency ms, the most influential factors were lease ttl sec (41.4%), cache size mb (30.9%), seal wrap threads (27.7%). The best observed value was 8.4 (at seal wrap threads = 4.5, cache size mb = 512, lease ttl sec = 30).
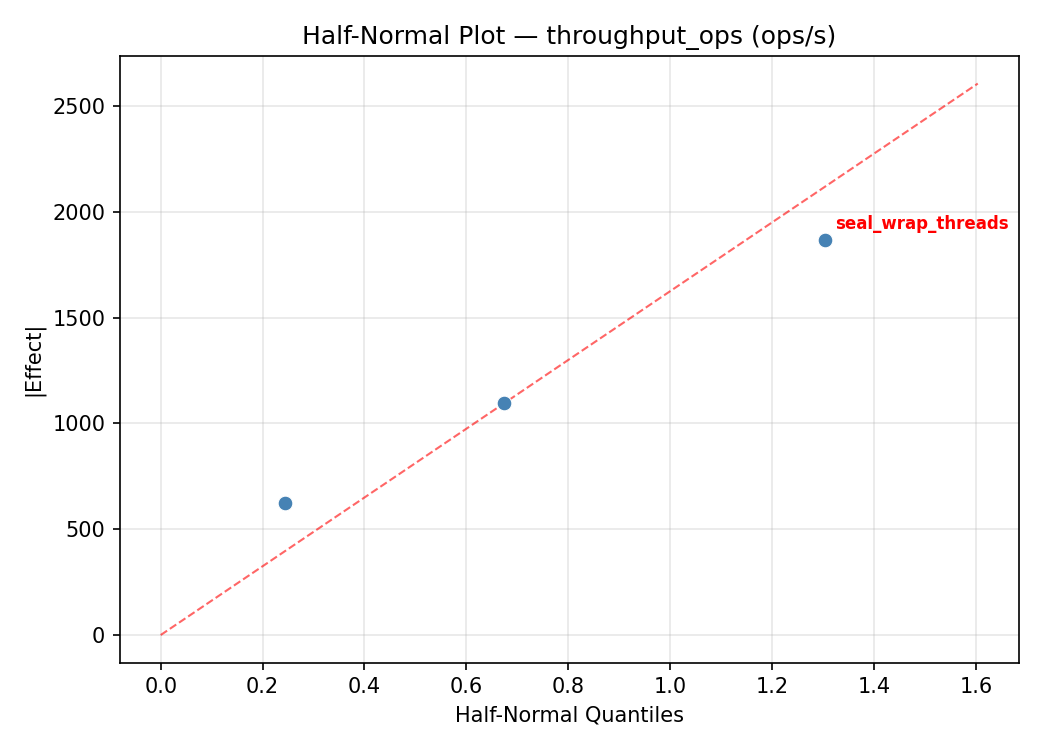
For throughput ops, the most influential factors were lease ttl sec (37.0%), seal wrap threads (32.6%), cache size mb (30.4%). The best observed value was 7690.0 (at seal wrap threads = 4.5, cache size mb = 512, lease ttl sec = 30).
Recommended Next Steps
- Run confirmation experiments at the predicted optimal settings to validate the model.
- Consider whether any fixed factors should be varied in a future study.
Experimental Setup
Factors
| Factor | Low | High | Unit |
|---|
seal_wrap_threads | 1 | 8 | threads |
cache_size_mb | 64 | 512 | MB |
lease_ttl_sec | 30 | 600 | sec |
Fixed: vault_backend = consul, seal_type = awskms
Responses
| Response | Direction | Unit |
|---|
read_latency_ms | ↓ minimize | ms |
throughput_ops | ↑ maximize | ops/s |
Configuration
{
"metadata": {
"name": "Secrets Vault Performance",
"description": "Box-Behnken design to optimize vault seal wrap threads, cache size, and lease TTL for latency and throughput"
},
"factors": [
{
"name": "seal_wrap_threads",
"levels": [
"1",
"8"
],
"type": "continuous",
"unit": "threads"
},
{
"name": "cache_size_mb",
"levels": [
"64",
"512"
],
"type": "continuous",
"unit": "MB"
},
{
"name": "lease_ttl_sec",
"levels": [
"30",
"600"
],
"type": "continuous",
"unit": "sec"
}
],
"fixed_factors": {
"vault_backend": "consul",
"seal_type": "awskms"
},
"responses": [
{
"name": "read_latency_ms",
"optimize": "minimize",
"unit": "ms"
},
{
"name": "throughput_ops",
"optimize": "maximize",
"unit": "ops/s"
}
],
"settings": {
"operation": "box_behnken",
"test_script": "use_cases/64_secrets_vault_performance/sim.sh"
}
}
Experimental Matrix
The Box-Behnken Design produces 15 runs. Each row is one experiment with specific factor settings.
| Run | seal_wrap_threads | cache_size_mb | lease_ttl_sec |
|---|
| 1 | 4.5 | 64 | 30 |
| 2 | 4.5 | 288 | 315 |
| 3 | 8 | 288 | 600 |
| 4 | 8 | 288 | 30 |
| 5 | 4.5 | 288 | 315 |
| 6 | 4.5 | 288 | 315 |
| 7 | 1 | 288 | 600 |
| 8 | 8 | 64 | 315 |
| 9 | 4.5 | 64 | 600 |
| 10 | 8 | 512 | 315 |
| 11 | 1 | 288 | 30 |
| 12 | 4.5 | 512 | 600 |
| 13 | 1 | 64 | 315 |
| 14 | 1 | 512 | 315 |
| 15 | 4.5 | 512 | 30 |
Step-by-Step Workflow
1
Preview the design
$ doe info --config use_cases/64_secrets_vault_performance/config.json
2
Generate the runner script
$ doe generate --config use_cases/64_secrets_vault_performance/config.json \
--output use_cases/64_secrets_vault_performance/results/run.sh --seed 42
3
Execute the experiments
$ bash use_cases/64_secrets_vault_performance/results/run.sh
4
Analyze results
$ doe analyze --config use_cases/64_secrets_vault_performance/config.json
5
Get optimization recommendations
$ doe optimize --config use_cases/64_secrets_vault_performance/config.json
6
Multi-objective optimization
With 2 competing responses, use --multi to find the best compromise via Derringer–Suich desirability.
$ doe optimize --config use_cases/64_secrets_vault_performance/config.json --multi
7
Generate the HTML report
$ doe report --config use_cases/64_secrets_vault_performance/config.json \
--output use_cases/64_secrets_vault_performance/results/report.html
Features Exercised
| Feature | Value |
|---|
| Design type | box_behnken |
| Factor types | continuous (all 3) |
| Arg style | double-dash |
| Responses | 2 (read_latency_ms ↓, throughput_ops ↑) |
| Total runs | 15 |
Analysis Results
Generated from actual experiment runs using the DOE Helper Tool.
Response: read_latency_ms
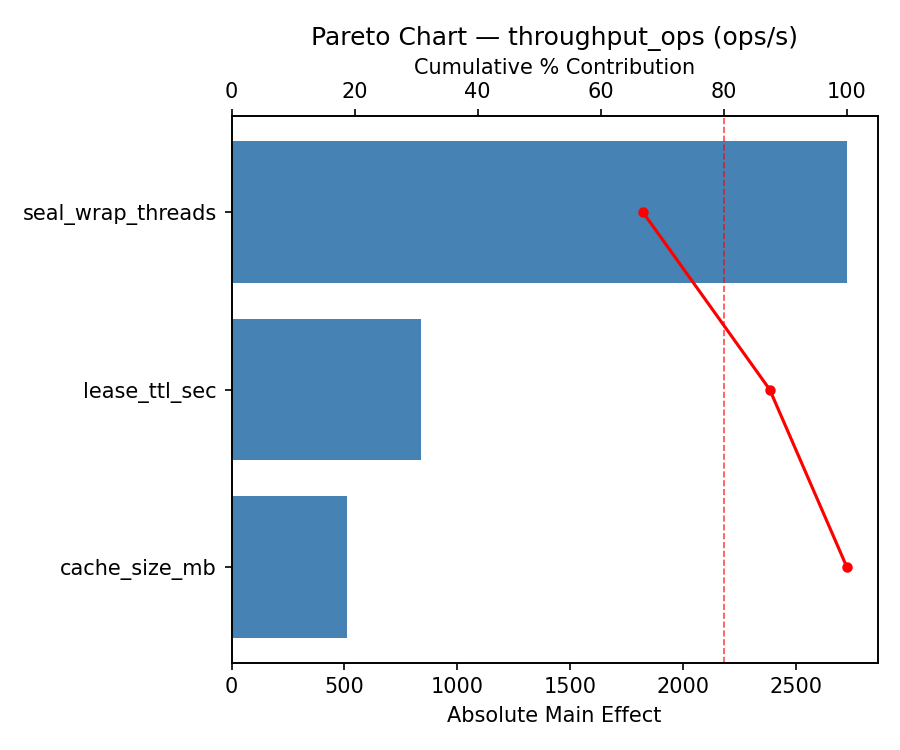
Top factors: lease_ttl_sec (41.4%), cache_size_mb (30.9%), seal_wrap_threads (27.7%).
ANOVA
| Source | DF | SS | MS | F | p-value |
|---|
| Source | DF | SS | MS | F | p-value |
| seal_wrap_threads | 2 | 41.0755 | 20.5378 | 1.010 | 0.4063 |
| cache_size_mb | 2 | 82.7327 | 41.3663 | 2.034 | 0.1931 |
| lease_ttl_sec | 2 | 91.7852 | 45.8926 | 2.257 | 0.1670 |
| Lack | of | Fit | 6 | 248.0772 | 41.3462 |
| Pure | Error | 2 | 40.6667 | | |
| Error | 8 | 288.7439 | 20.3333 | | |
| Total | 14 | 504.3373 | 36.0241 | | |
Pareto Chart
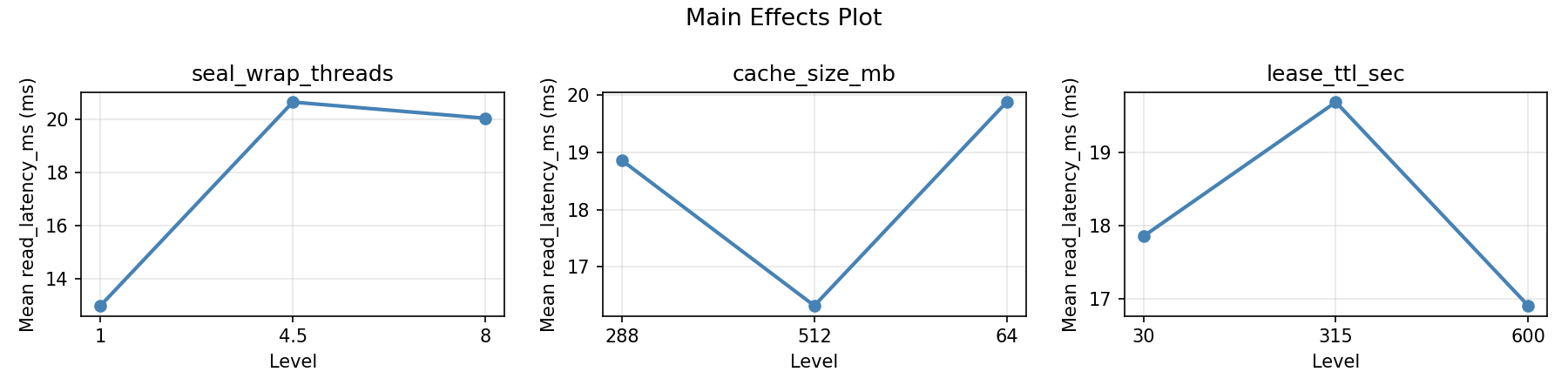
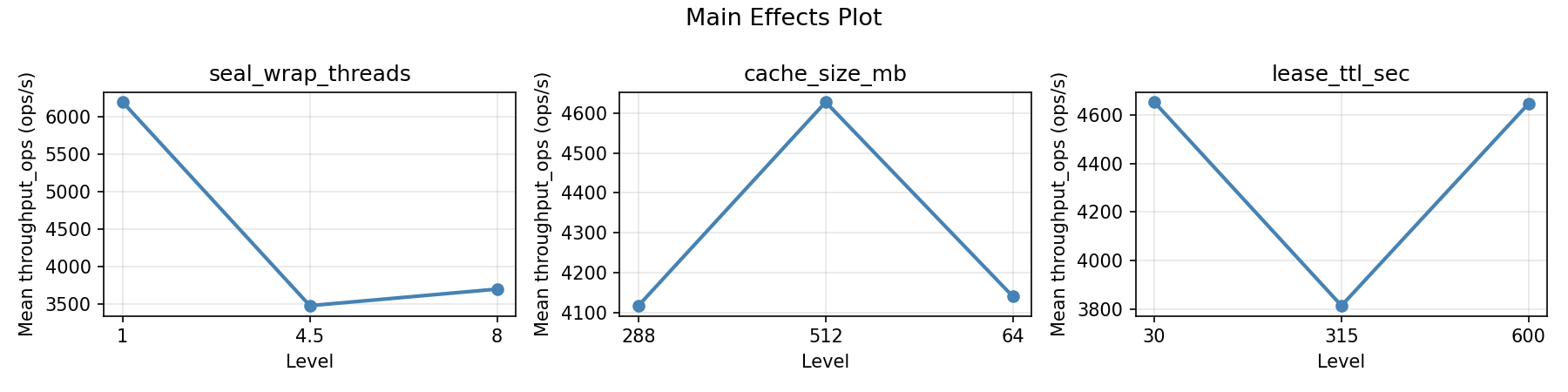
Main Effects Plot
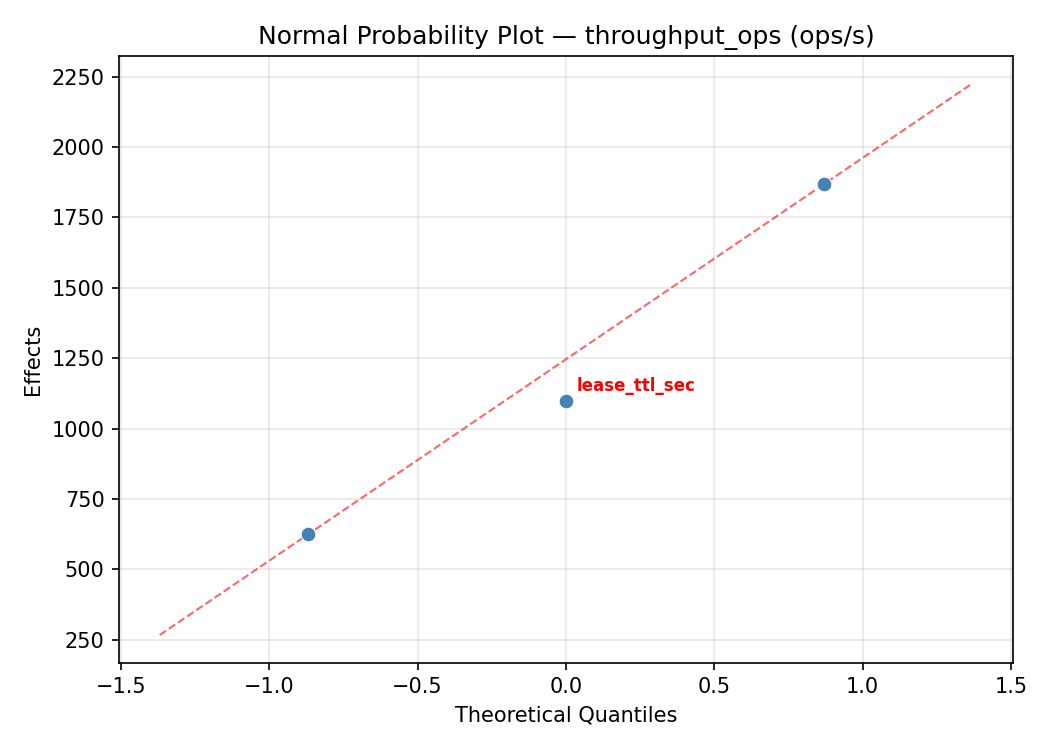
Normal Probability Plot of Effects
Half-Normal Plot of Effects
Model Diagnostics
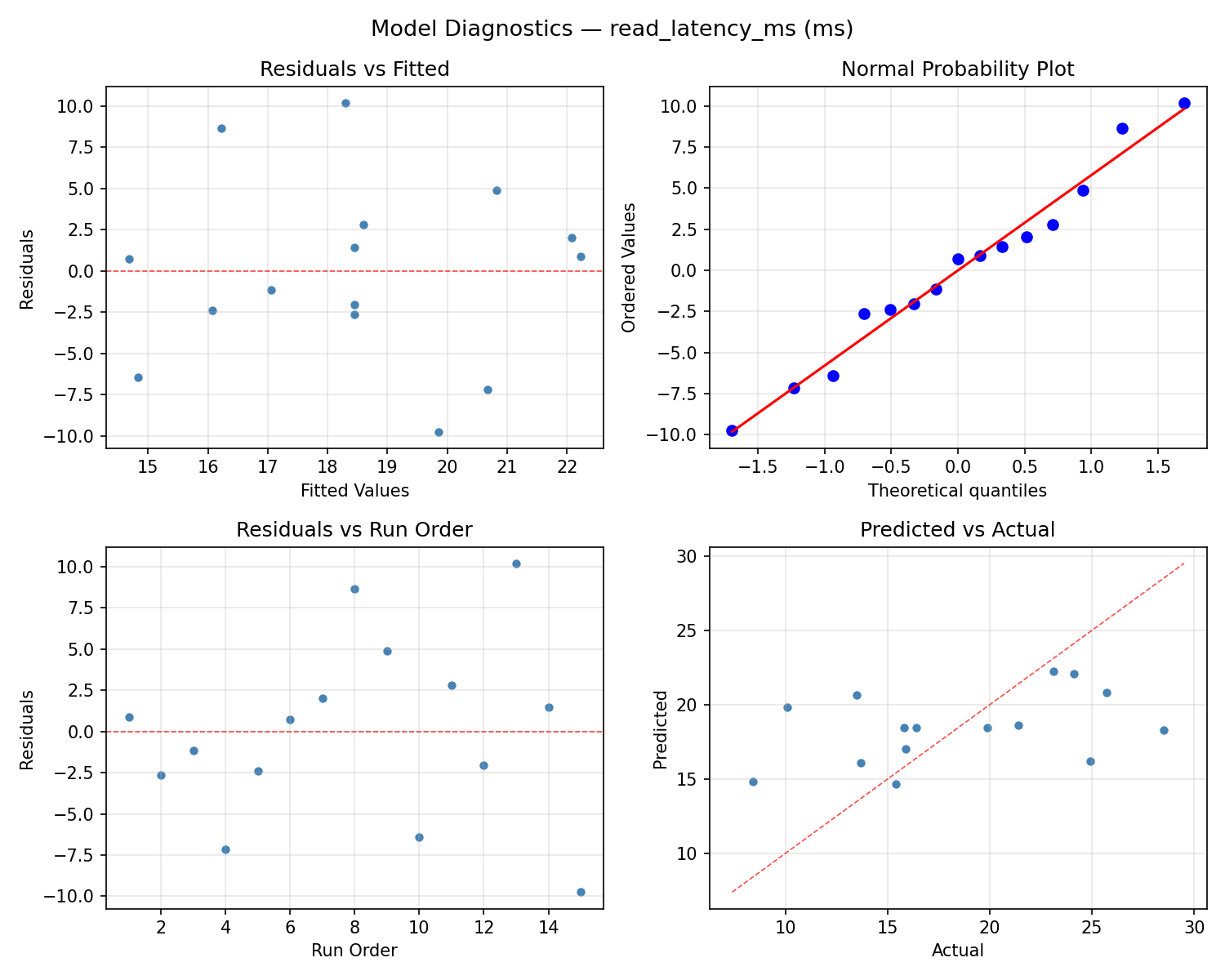
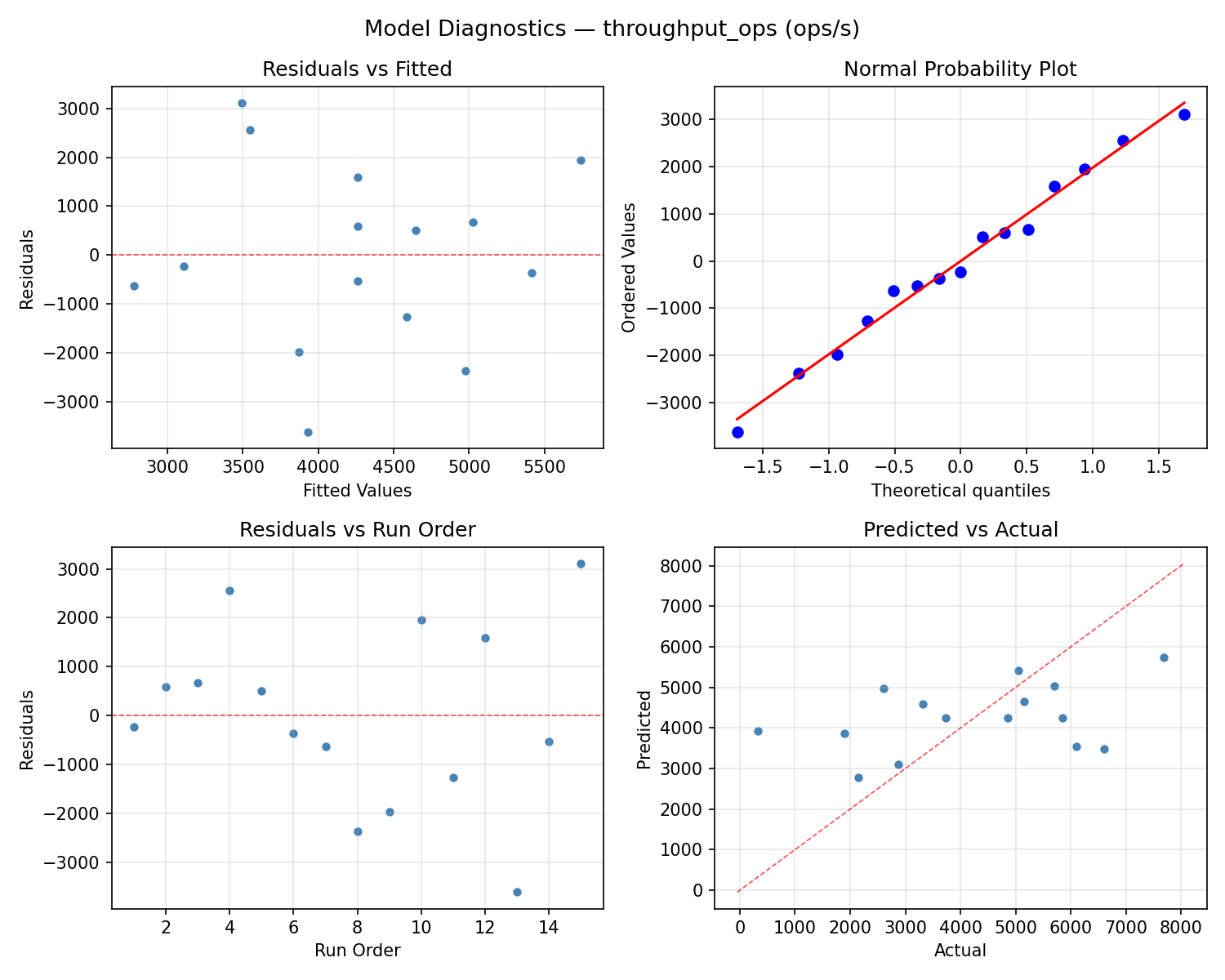
Response: throughput_ops
Top factors: lease_ttl_sec (37.0%), seal_wrap_threads (32.6%), cache_size_mb (30.4%).
ANOVA
| Source | DF | SS | MS | F | p-value |
|---|
| Source | DF | SS | MS | F | p-value |
| seal_wrap_threads | 2 | 5990600.5190 | 2995300.2595 | 1.225 | 0.3436 |
| cache_size_mb | 2 | 7028446.8762 | 3514223.4381 | 1.437 | 0.2930 |
| lease_ttl_sec | 2 | 9998890.5190 | 4999445.2595 | 2.044 | 0.1919 |
| Lack | of | Fit | 6 | 30444503.8190 | 5074083.9698 |
| Pure | Error | 2 | 4892234.0000 | | |
| Error | 8 | 35336737.8190 | 2446117.0000 | | |
| Total | 14 | 58354675.7333 | 4168191.1238 | | |
Pareto Chart
Main Effects Plot
Normal Probability Plot of Effects
Half-Normal Plot of Effects
Model Diagnostics
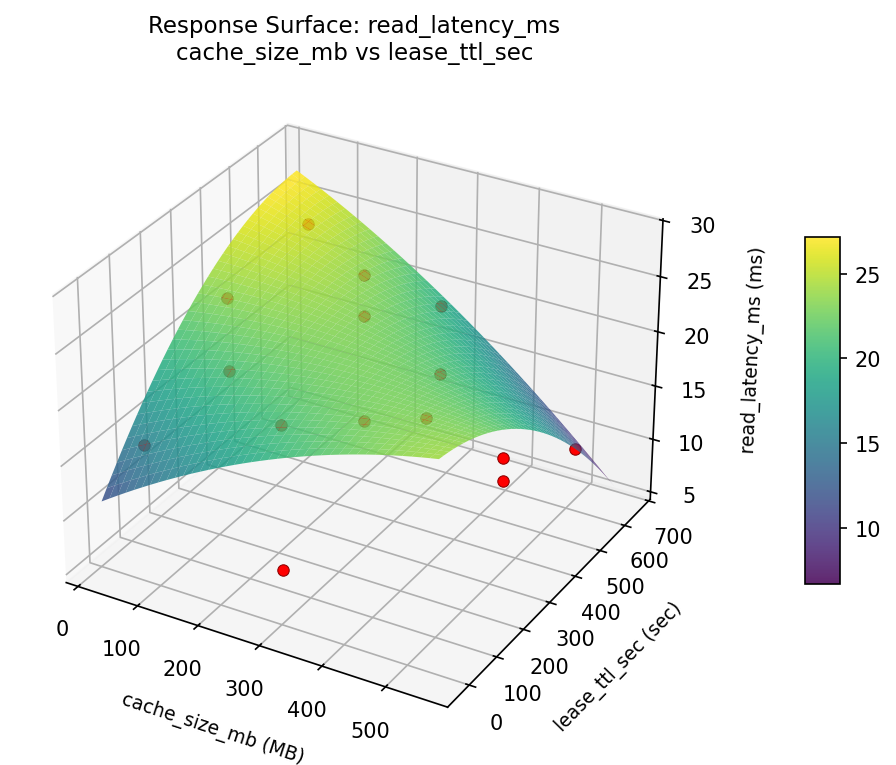
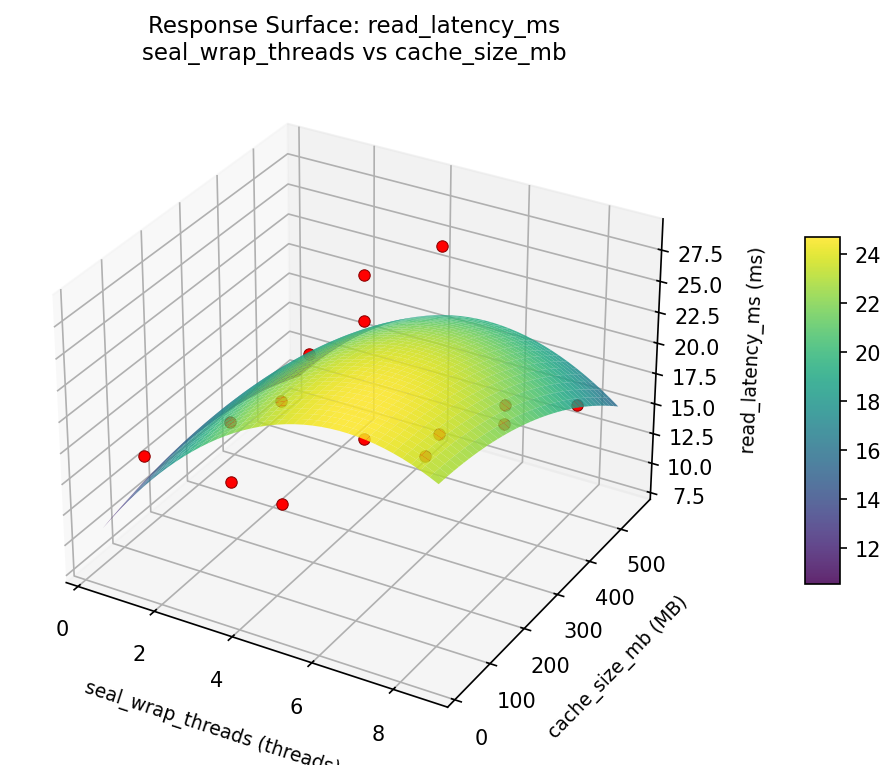
Response Surface Plots
3D surfaces fitted with quadratic RSM. Red dots are observed data points.
read latency ms cache size mb vs lease ttl sec
read latency ms seal wrap threads vs cache size mb
read latency ms seal wrap threads vs lease ttl sec
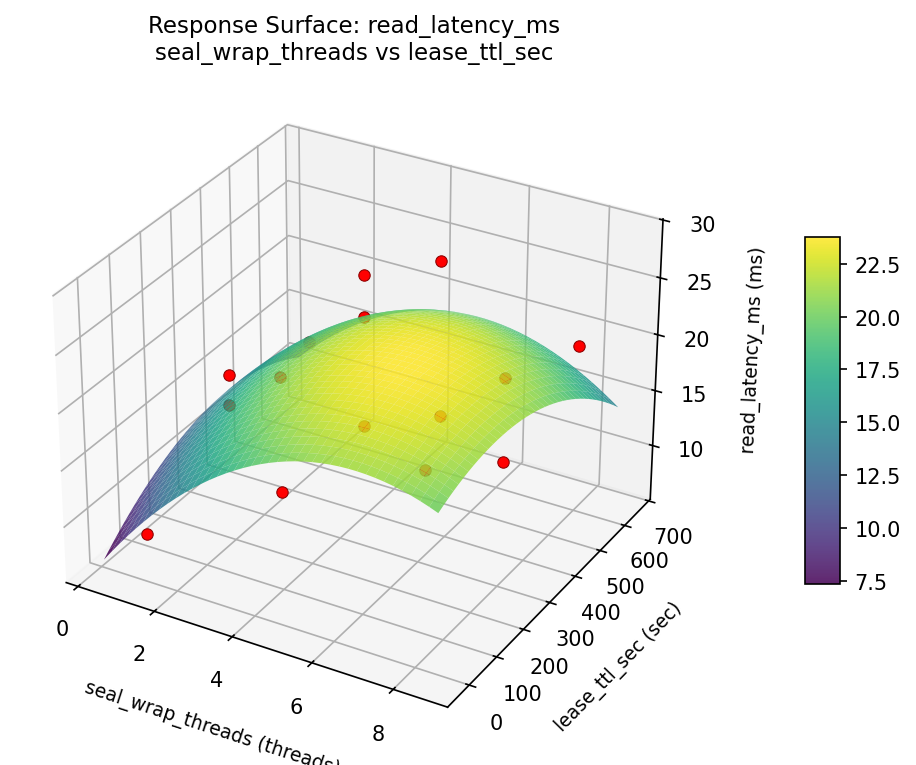
throughput ops cache size mb vs lease ttl sec
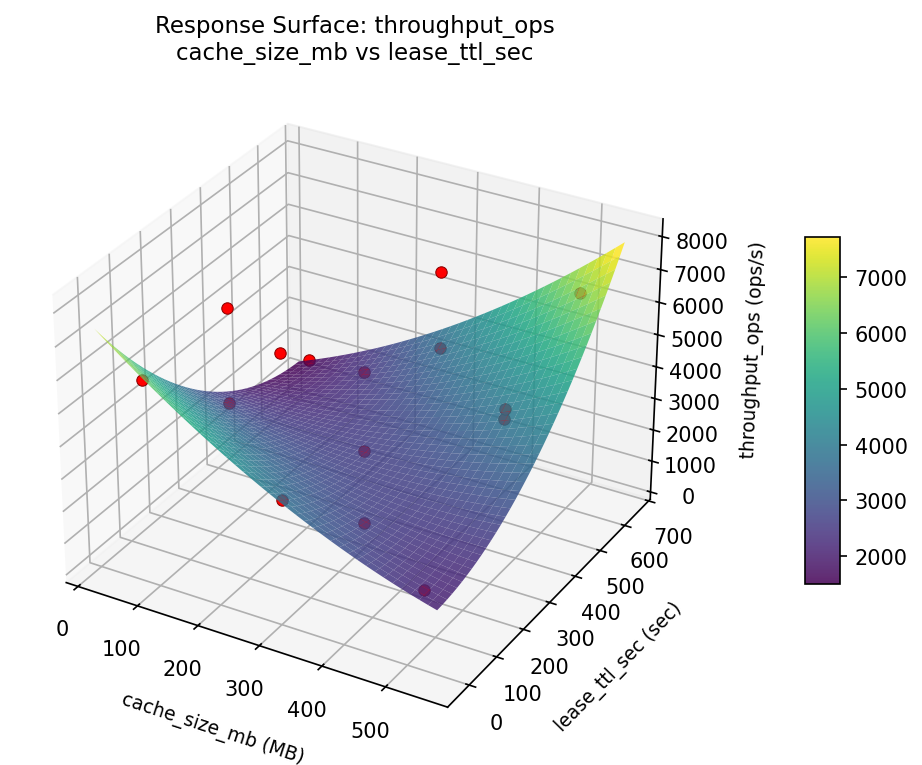
throughput ops seal wrap threads vs cache size mb
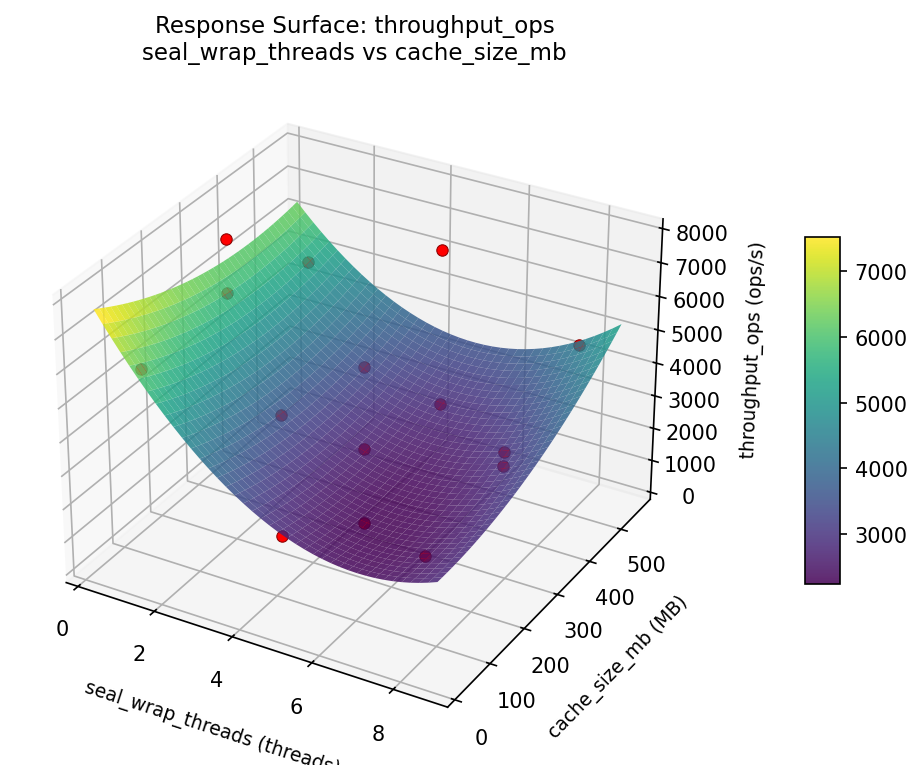
throughput ops seal wrap threads vs lease ttl sec
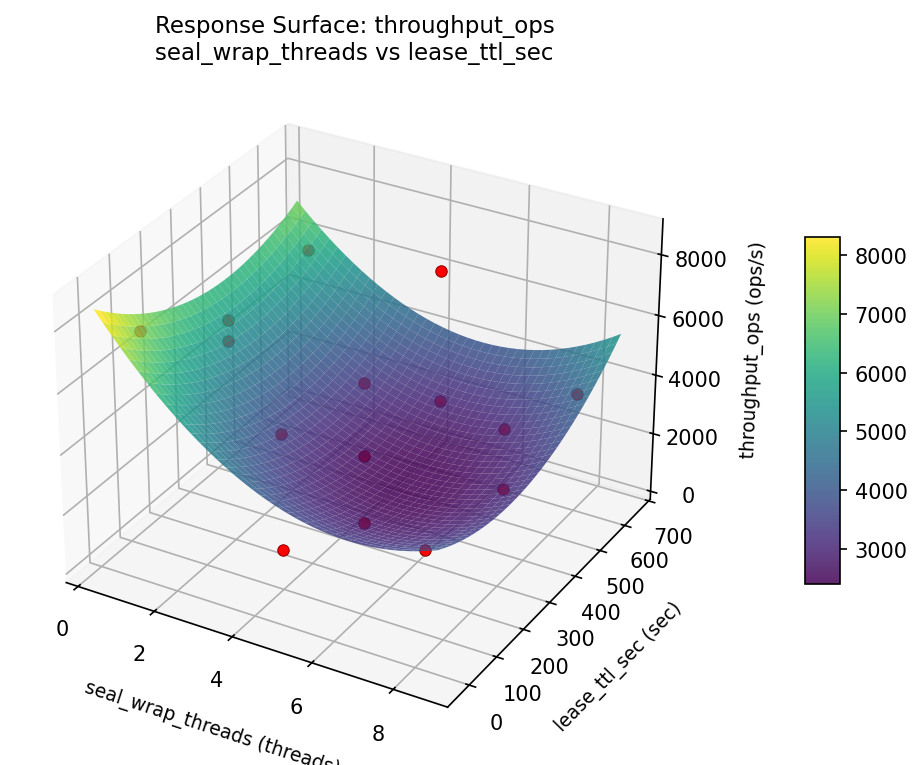
Multi-Objective Optimization
When responses compete, Derringer–Suich desirability finds the best compromise.
Each response is scaled to a 0–1 desirability, then combined via a weighted geometric mean.
Overall Desirability
D = 0.9545
Per-Response Desirability
| Response | Weight | Desirability | Predicted | Dir |
|---|
read_latency_ms |
1.0 |
|
8.40 0.9545 8.40 ms |
↓ |
throughput_ops |
1.5 |
|
7690.00 0.9545 7690.00 ops/s |
↑ |
Recommended Settings
| Factor | Value |
|---|
seal_wrap_threads | 4.5 threads |
cache_size_mb | 288 MB |
lease_ttl_sec | 315 sec |
Source: from observed run #10
Trade-off Summary
Sacrifice = how much worse than single-objective best.
| Response | Predicted | Best Observed | Sacrifice |
|---|
throughput_ops | 7690.00 | 7690.00 | +0.00 |
Top 3 Runs by Desirability
| Run | D | Factor Settings |
|---|
| #15 | 0.8429 | seal_wrap_threads=8, cache_size_mb=288, lease_ttl_sec=30 |
| #4 | 0.7446 | seal_wrap_threads=8, cache_size_mb=64, lease_ttl_sec=315 |
Model Quality
| Response | R² | Type |
|---|
throughput_ops | 0.4807 | linear |
Full Multi-Objective Output
============================================================
MULTI-OBJECTIVE OPTIMIZATION
Method: Derringer-Suich Desirability Function
============================================================
Overall desirability: D = 0.9545
Response Weight Desirability Predicted Direction
---------------------------------------------------------------------
read_latency_ms 1.0 0.9545 8.40 ms ↓
throughput_ops 1.5 0.9545 7690.00 ops/s ↑
Recommended settings:
seal_wrap_threads = 4.5 threads
cache_size_mb = 288 MB
lease_ttl_sec = 315 sec
(from observed run #10)
Trade-off summary:
read_latency_ms: 8.40 (best observed: 8.40, sacrifice: +0.00)
throughput_ops: 7690.00 (best observed: 7690.00, sacrifice: +0.00)
Model quality:
read_latency_ms: R² = 0.4983 (linear)
throughput_ops: R² = 0.4807 (linear)
Top 3 observed runs by overall desirability:
1. Run #10 (D=0.9545): seal_wrap_threads=4.5, cache_size_mb=288, lease_ttl_sec=315
2. Run #15 (D=0.8429): seal_wrap_threads=8, cache_size_mb=288, lease_ttl_sec=30
3. Run #4 (D=0.7446): seal_wrap_threads=8, cache_size_mb=64, lease_ttl_sec=315
Full Analysis Output
=== Main Effects: read_latency_ms ===
Factor Effect Std Error % Contribution
--------------------------------------------------------------
lease_ttl_sec 6.6000 1.5497 41.4%
cache_size_mb 4.9321 1.5497 30.9%
seal_wrap_threads 4.4250 1.5497 27.7%
=== ANOVA Table: read_latency_ms ===
Source DF SS MS F p-value
-----------------------------------------------------------------------------
seal_wrap_threads 2 41.0755 20.5378 1.010 0.4063
cache_size_mb 2 82.7327 41.3663 2.034 0.1931
lease_ttl_sec 2 91.7852 45.8926 2.257 0.1670
Lack of Fit 6 248.0772 41.3462 2.033 0.3658
Pure Error 2 40.6667 20.3333
Error 8 288.7439 20.3333
Total 14 504.3373 36.0241
=== Summary Statistics: read_latency_ms ===
seal_wrap_threads:
Level N Mean Std Min Max
------------------------------------------------------------
1 4 21.0000 3.8962 15.4000 24.1000
4.5 7 18.0714 6.6708 10.1000 28.5000
8 4 16.5750 7.0882 8.4000 25.7000
cache_size_mb:
Level N Mean Std Min Max
------------------------------------------------------------
288 7 20.9571 4.0024 15.8000 25.7000
512 4 16.5000 8.5374 8.4000 28.5000
64 4 16.0250 5.9673 10.1000 24.1000
lease_ttl_sec:
Level N Mean Std Min Max
------------------------------------------------------------
30 4 22.2750 6.5383 13.5000 28.5000
315 7 17.8571 5.6888 8.4000 24.9000
600 4 15.6750 5.4811 10.1000 23.1000
=== Main Effects: throughput_ops ===
Factor Effect Std Error % Contribution
--------------------------------------------------------------
lease_ttl_sec 1958.5000 527.1427 37.0%
seal_wrap_threads 1724.5000 527.1427 32.6%
cache_size_mb 1605.3571 527.1427 30.4%
=== ANOVA Table: throughput_ops ===
Source DF SS MS F p-value
-----------------------------------------------------------------------------
seal_wrap_threads 2 5990600.5190 2995300.2595 1.225 0.3436
cache_size_mb 2 7028446.8762 3514223.4381 1.437 0.2930
lease_ttl_sec 2 9998890.5190 4999445.2595 2.044 0.1919
Lack of Fit 6 30444503.8190 5074083.9698 2.074 0.3605
Pure Error 2 4892234.0000 2446117.0000
Error 8 35336737.8190 2446117.0000
Total 14 58354675.7333 4168191.1238
=== Summary Statistics: throughput_ops ===
seal_wrap_threads:
Level N Mean Std Min Max
------------------------------------------------------------
1 4 3347.2500 1231.1186 2148.0000 5045.0000
4.5 7 4316.5714 2245.7954 320.0000 6603.0000
8 4 5071.7500 2419.0587 1901.0000 7690.0000
cache_size_mb:
Level N Mean Std Min Max
------------------------------------------------------------
288 7 3569.1429 1319.8840 1901.0000 5696.0000
512 4 4552.5000 3074.8184 320.0000 7690.0000
64 4 5174.5000 2042.0693 2148.0000 6603.0000
lease_ttl_sec:
Level N Mean Std Min Max
------------------------------------------------------------
30 4 2911.7500 2455.3634 320.0000 6102.0000
315 7 4680.5714 1966.0653 2148.0000 7690.0000
600 4 4870.2500 1535.8905 2872.0000 6603.0000
Optimization Recommendations
=== Optimization: read_latency_ms ===
Direction: minimize
Best observed run: #10
seal_wrap_threads = 4.5
cache_size_mb = 512
lease_ttl_sec = 30
Value: 8.4
RSM Model (linear, R² = 0.5202, Adj R² = 0.3894):
Coefficients:
intercept +18.4533
seal_wrap_threads +0.2625
cache_size_mb -5.5500
lease_ttl_sec -1.3875
RSM Model (quadratic, R² = 0.6656, Adj R² = 0.0638):
Coefficients:
intercept +18.6000
seal_wrap_threads +0.2625
cache_size_mb -5.5500
lease_ttl_sec -1.3875
seal_wrap_threads*cache_size_mb +2.2750
seal_wrap_threads*lease_ttl_sec -0.6500
cache_size_mb*lease_ttl_sec -0.0250
seal_wrap_threads^2 +1.7000
cache_size_mb^2 -2.9750
lease_ttl_sec^2 +1.0000
Curvature analysis:
cache_size_mb coef=-2.9750 concave (has a maximum)
seal_wrap_threads coef=+1.7000 convex (has a minimum)
lease_ttl_sec coef=+1.0000 convex (has a minimum)
Notable interactions:
seal_wrap_threads*cache_size_mb coef=+2.2750 (synergistic)
seal_wrap_threads*lease_ttl_sec coef=-0.6500 (antagonistic)
Predicted optimum (from linear model, at observed points):
seal_wrap_threads = 4.5
cache_size_mb = 64
lease_ttl_sec = 30
Predicted value: 25.3908
Surface optimum (via L-BFGS-B, linear model):
seal_wrap_threads = 1
cache_size_mb = 512
lease_ttl_sec = 600
Predicted value: 11.2533
Model quality: Moderate fit — use predictions directionally, not precisely.
Factor importance:
1. cache_size_mb (effect: 11.1, contribution: 69.5%)
2. lease_ttl_sec (effect: 2.8, contribution: 17.4%)
3. seal_wrap_threads (effect: 2.1, contribution: 13.2%)
=== Optimization: throughput_ops ===
Direction: maximize
Best observed run: #10
seal_wrap_threads = 4.5
cache_size_mb = 512
lease_ttl_sec = 30
Value: 7690.0
RSM Model (linear, R² = 0.3569, Adj R² = 0.1814):
Coefficients:
intercept +4259.4667
seal_wrap_threads +72.1250
cache_size_mb +1540.8750
lease_ttl_sec +472.7500
RSM Model (quadratic, R² = 0.5503, Adj R² = -0.2592):
Coefficients:
intercept +4231.6667
seal_wrap_threads +72.1250
cache_size_mb +1540.8750
lease_ttl_sec +472.7500
seal_wrap_threads*cache_size_mb -749.2500
seal_wrap_threads*lease_ttl_sec +423.5000
cache_size_mb*lease_ttl_sec -205.0000
seal_wrap_threads^2 -658.7083
cache_size_mb^2 +1177.7917
lease_ttl_sec^2 -466.9583
Curvature analysis:
cache_size_mb coef=+1177.7917 convex (has a minimum)
seal_wrap_threads coef=-658.7083 concave (has a maximum)
lease_ttl_sec coef=-466.9583 concave (has a maximum)
Notable interactions:
seal_wrap_threads*cache_size_mb coef=-749.2500 (antagonistic)
seal_wrap_threads*lease_ttl_sec coef=+423.5000 (synergistic)
cache_size_mb*lease_ttl_sec coef=-205.0000 (antagonistic)
Predicted optimum (from linear model, at observed points):
seal_wrap_threads = 4.5
cache_size_mb = 512
lease_ttl_sec = 600
Predicted value: 6273.0917
Surface optimum (via L-BFGS-B, linear model):
seal_wrap_threads = 8
cache_size_mb = 512
lease_ttl_sec = 600
Predicted value: 6345.2167
Model quality: Weak fit — consider adding center points or using a different design.
Factor importance:
1. cache_size_mb (effect: 3081.8, contribution: 63.7%)
2. lease_ttl_sec (effect: 976.8, contribution: 20.2%)
3. seal_wrap_threads (effect: 781.6, contribution: 16.1%)