Summary
This experiment investigates edge inference quantization. Plackett-Burman screening of 6 edge ML inference parameters for latency and accuracy loss.
The design varies 6 factors: weight bits (bits), ranging from 4 to 16, activation bits (bits), ranging from 4 to 16, batch size (samples), ranging from 1 to 32, num threads (threads), ranging from 1 to 4, cache size kb (KB), ranging from 64 to 512, and memory pool mb (MB), ranging from 16 to 128. The goal is to optimize 2 responses: inference latency ms (ms) (minimize) and accuracy loss pct (%) (minimize). Fixed conditions held constant across all runs include framework = tflite, model = mobilenet_v2.
A Plackett-Burman screening design was used to efficiently test 6 factors in only 8 runs. This design assumes interactions are negligible and focuses on identifying the most influential main effects.
Key Findings
For inference latency ms, the most influential factors were memory pool mb (35.1%), cache size kb (25.0%), weight bits (14.0%). The best observed value was 5.3 (at weight bits = 16, activation bits = 4, batch size = 1).
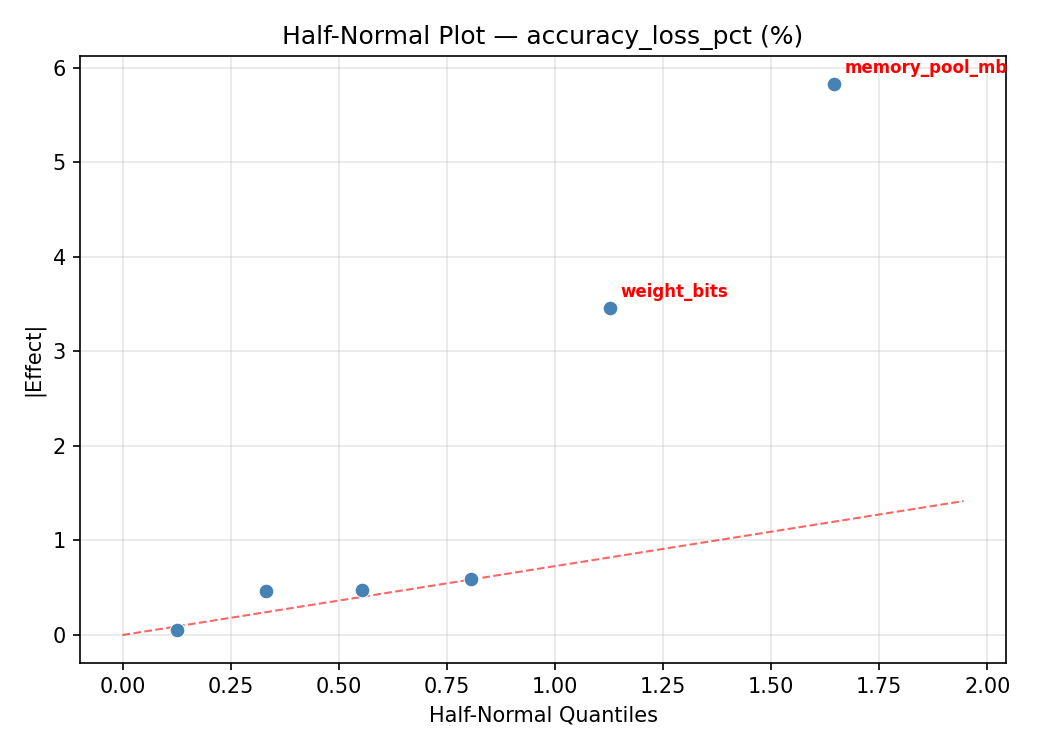
For accuracy loss pct, the most influential factors were memory pool mb (49.1%), weight bits (32.3%), cache size kb (9.7%). The best observed value was 1.42 (at weight bits = 4, activation bits = 16, batch size = 1).
Recommended Next Steps
- Follow up with a response surface design (CCD or Box-Behnken) on the top 3–4 factors to model curvature and find the true optimum.
- Consider whether any fixed factors should be varied in a future study.
- The screening results can guide factor reduction — drop factors contributing less than 5% and re-run with a smaller, more focused design.
Experimental Setup
Factors
| Factor | Low | High | Unit |
|---|
weight_bits | 4 | 16 | bits |
activation_bits | 4 | 16 | bits |
batch_size | 1 | 32 | samples |
num_threads | 1 | 4 | threads |
cache_size_kb | 64 | 512 | KB |
memory_pool_mb | 16 | 128 | MB |
Fixed: framework = tflite, model = mobilenet_v2
Responses
| Response | Direction | Unit |
|---|
inference_latency_ms | ↓ minimize | ms |
accuracy_loss_pct | ↓ minimize | % |
Configuration
{
"metadata": {
"name": "Edge Inference Quantization",
"description": "Plackett-Burman screening of 6 edge ML inference parameters for latency and accuracy loss"
},
"factors": [
{
"name": "weight_bits",
"levels": [
"4",
"16"
],
"type": "continuous",
"unit": "bits"
},
{
"name": "activation_bits",
"levels": [
"4",
"16"
],
"type": "continuous",
"unit": "bits"
},
{
"name": "batch_size",
"levels": [
"1",
"32"
],
"type": "continuous",
"unit": "samples"
},
{
"name": "num_threads",
"levels": [
"1",
"4"
],
"type": "continuous",
"unit": "threads"
},
{
"name": "cache_size_kb",
"levels": [
"64",
"512"
],
"type": "continuous",
"unit": "KB"
},
{
"name": "memory_pool_mb",
"levels": [
"16",
"128"
],
"type": "continuous",
"unit": "MB"
}
],
"fixed_factors": {
"framework": "tflite",
"model": "mobilenet_v2"
},
"responses": [
{
"name": "inference_latency_ms",
"optimize": "minimize",
"unit": "ms"
},
{
"name": "accuracy_loss_pct",
"optimize": "minimize",
"unit": "%"
}
],
"settings": {
"operation": "plackett_burman",
"test_script": "use_cases/71_edge_inference_quantization/sim.sh"
}
}
Experimental Matrix
The Plackett-Burman Design produces 8 runs. Each row is one experiment with specific factor settings.
| Run | weight_bits | activation_bits | batch_size | num_threads | cache_size_kb | memory_pool_mb |
|---|
| 1 | 16 | 16 | 32 | 1 | 64 | 16 |
| 2 | 4 | 4 | 32 | 4 | 64 | 16 |
| 3 | 4 | 16 | 1 | 4 | 64 | 128 |
| 4 | 16 | 16 | 32 | 4 | 512 | 128 |
| 5 | 4 | 16 | 1 | 1 | 512 | 16 |
| 6 | 16 | 4 | 1 | 4 | 512 | 16 |
| 7 | 4 | 4 | 32 | 1 | 512 | 128 |
| 8 | 16 | 4 | 1 | 1 | 64 | 128 |
Step-by-Step Workflow
1
Preview the design
$ doe info --config use_cases/71_edge_inference_quantization/config.json
2
Generate the runner script
$ doe generate --config use_cases/71_edge_inference_quantization/config.json \
--output use_cases/71_edge_inference_quantization/results/run.sh --seed 42
3
Execute the experiments
$ bash use_cases/71_edge_inference_quantization/results/run.sh
4
Analyze results
$ doe analyze --config use_cases/71_edge_inference_quantization/config.json
5
Get optimization recommendations
$ doe optimize --config use_cases/71_edge_inference_quantization/config.json
6
Multi-objective optimization
With 2 competing responses, use --multi to find the best compromise via Derringer–Suich desirability.
$ doe optimize --config use_cases/71_edge_inference_quantization/config.json --multi
7
Generate the HTML report
$ doe report --config use_cases/71_edge_inference_quantization/config.json \
--output use_cases/71_edge_inference_quantization/results/report.html
Features Exercised
| Feature | Value |
|---|
| Design type | plackett_burman |
| Factor types | continuous (all 6) |
| Arg style | double-dash |
| Responses | 2 (inference_latency_ms ↓, accuracy_loss_pct ↓) |
| Total runs | 8 |
Analysis Results
Generated from actual experiment runs using the DOE Helper Tool.
Response: inference_latency_ms
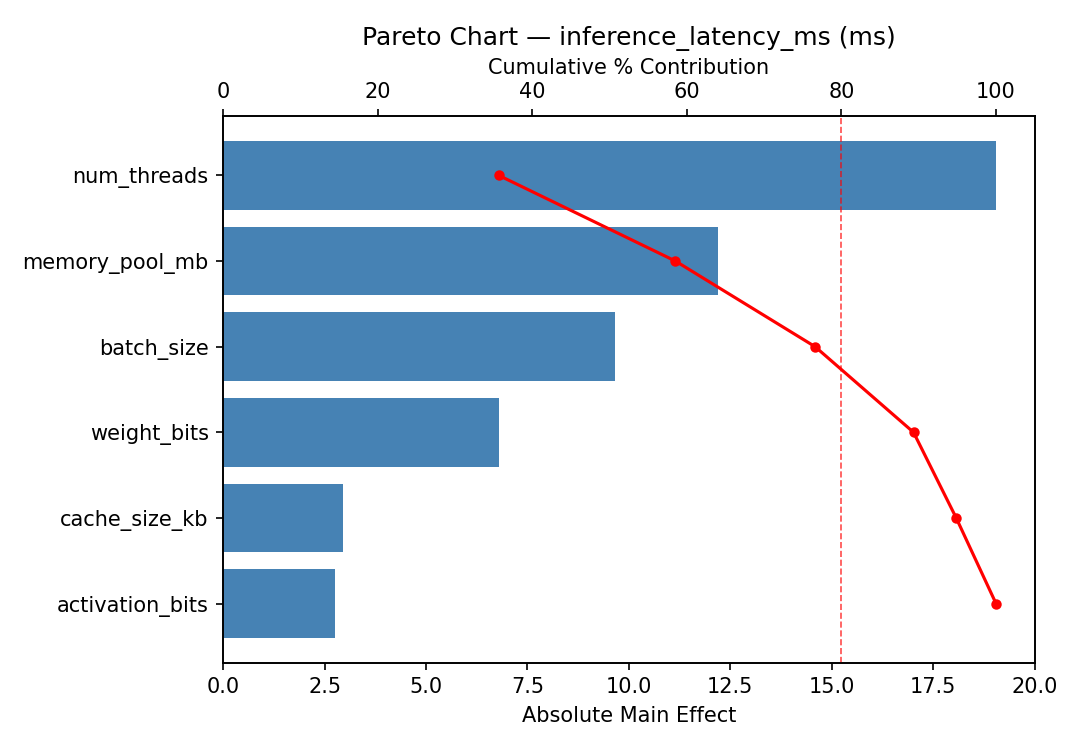
Top factors: memory_pool_mb (35.1%), cache_size_kb (25.0%), weight_bits (14.0%).
ANOVA
| Source | DF | SS | MS | F | p-value |
|---|
| Source | DF | SS | MS | F | p-value |
| weight_bits | 1 | 47.0450 | 47.0450 | 0.868 | 0.3825 |
| activation_bits | 1 | 15.1250 | 15.1250 | 0.279 | 0.6136 |
| batch_size | 1 | 8.0000 | 8.0000 | 0.148 | 0.7122 |
| num_threads | 1 | 36.1250 | 36.1250 | 0.667 | 0.4411 |
| cache_size_kb | 1 | 151.3800 | 151.3800 | 2.794 | 0.1386 |
| memory_pool_mb | 1 | 297.6800 | 297.6800 | 5.494 | 0.0516 |
| weight_bits*activation_bits | 1 | 8.0000 | 8.0000 | 0.148 | 0.7122 |
| weight_bits*batch_size | 1 | 15.1250 | 15.1250 | 0.279 | 0.6136 |
| weight_bits*num_threads | 1 | 151.3800 | 151.3800 | 2.794 | 0.1386 |
| weight_bits*cache_size_kb | 1 | 36.1250 | 36.1250 | 0.667 | 0.4411 |
| weight_bits*memory_pool_mb | 1 | 1017.0050 | 1017.0050 | 18.768 | 0.0034 |
| activation_bits*batch_size | 1 | 47.0450 | 47.0450 | 0.868 | 0.3825 |
| activation_bits*num_threads | 1 | 297.6800 | 297.6800 | 5.494 | 0.0516 |
| activation_bits*cache_size_kb | 1 | 1017.0050 | 1017.0050 | 18.768 | 0.0034 |
| activation_bits*memory_pool_mb | 1 | 36.1250 | 36.1250 | 0.667 | 0.4411 |
| batch_size*num_threads | 1 | 1017.0050 | 1017.0050 | 18.768 | 0.0034 |
| batch_size*cache_size_kb | 1 | 297.6800 | 297.6800 | 5.494 | 0.0516 |
| batch_size*memory_pool_mb | 1 | 151.3800 | 151.3800 | 2.794 | 0.1386 |
| num_threads*cache_size_kb | 1 | 47.0450 | 47.0450 | 0.868 | 0.3825 |
| num_threads*memory_pool_mb | 1 | 15.1250 | 15.1250 | 0.279 | 0.6136 |
| cache_size_kb*memory_pool_mb | 1 | 8.0000 | 8.0000 | 0.148 | 0.7122 |
| Error | (Lenth | PSE) | 7 | 379.3125 | 54.1875 |
| Total | 7 | 1572.3600 | 224.6229 | | |
Pareto Chart
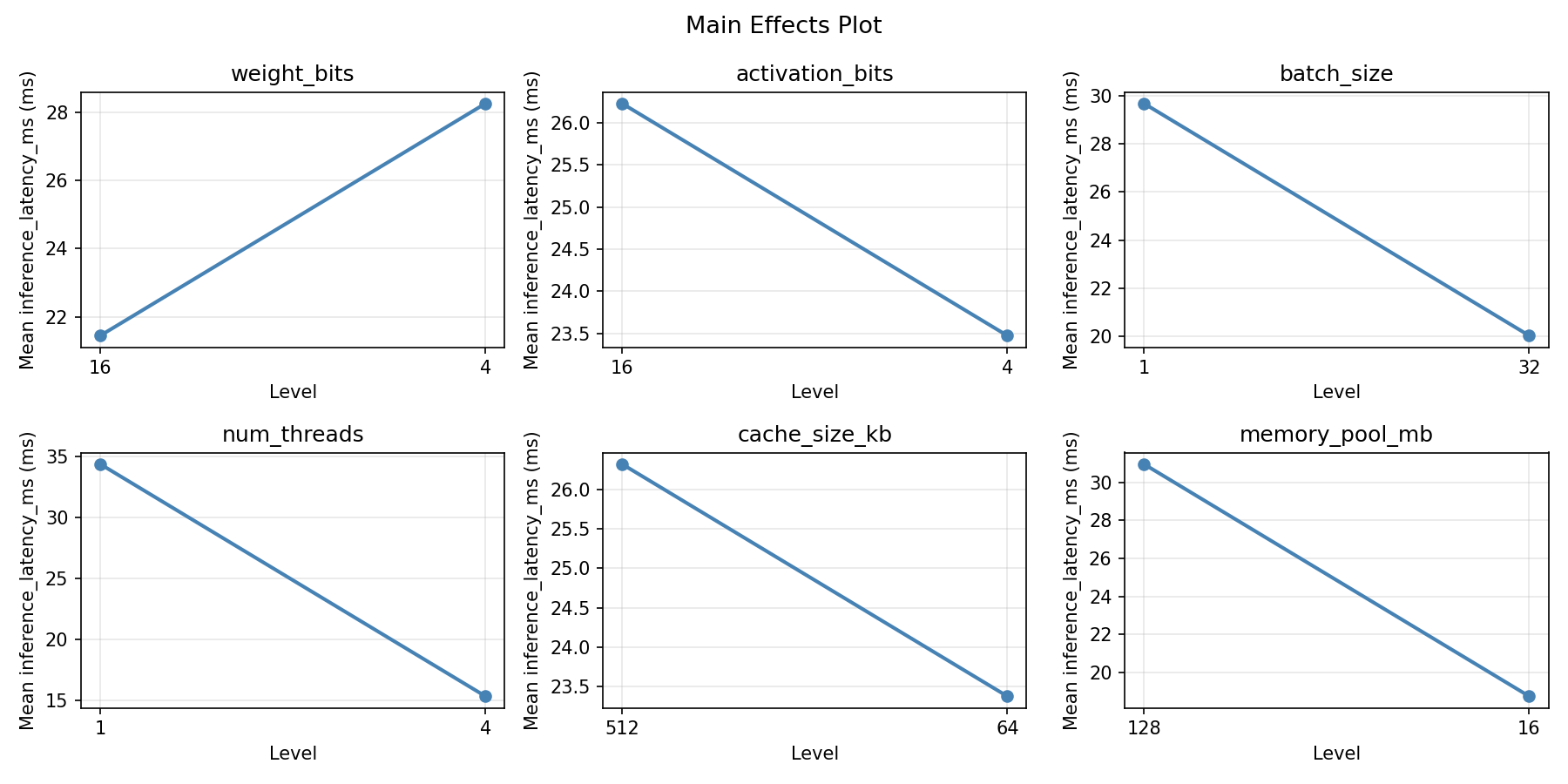
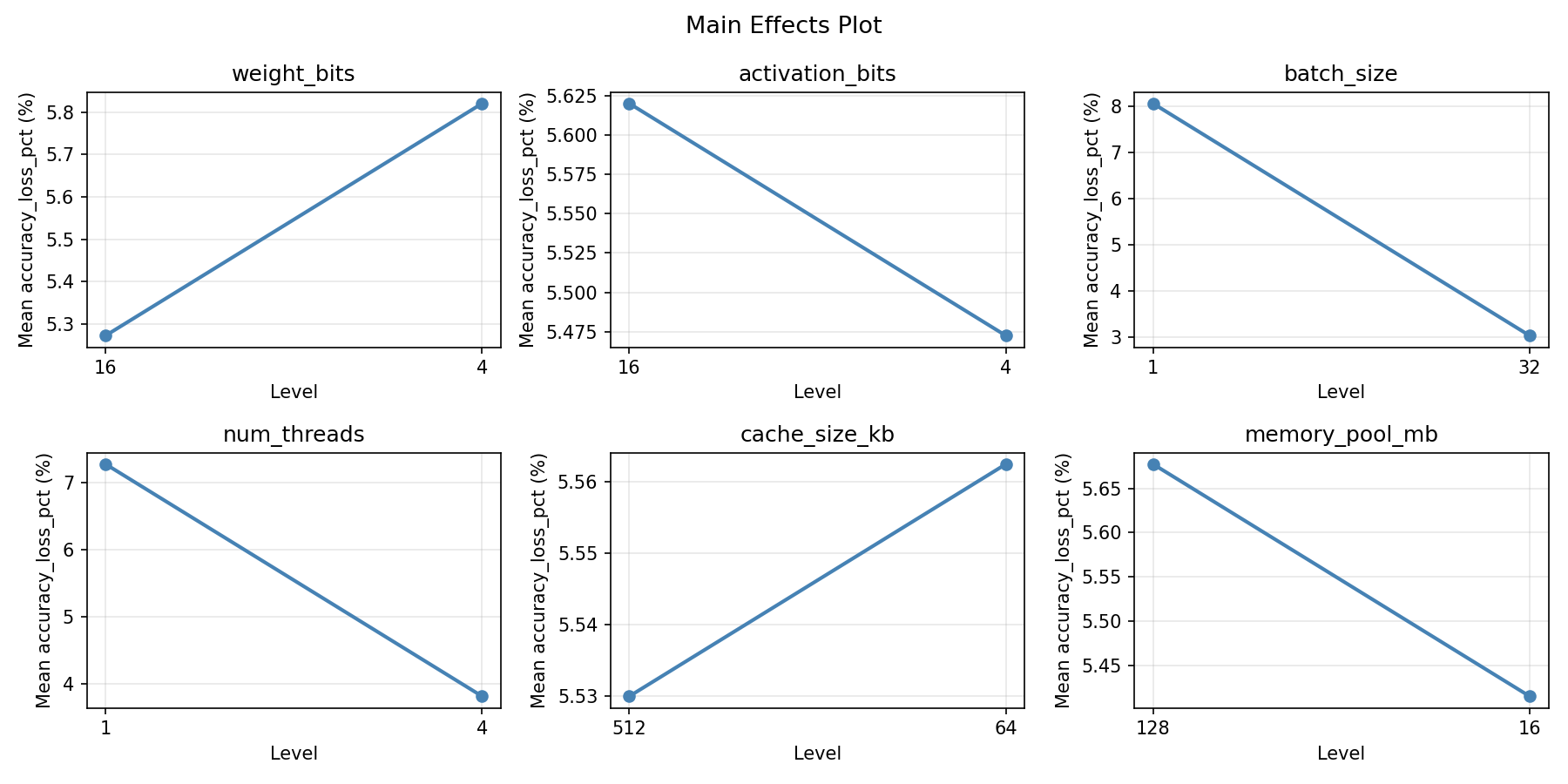
Main Effects Plot
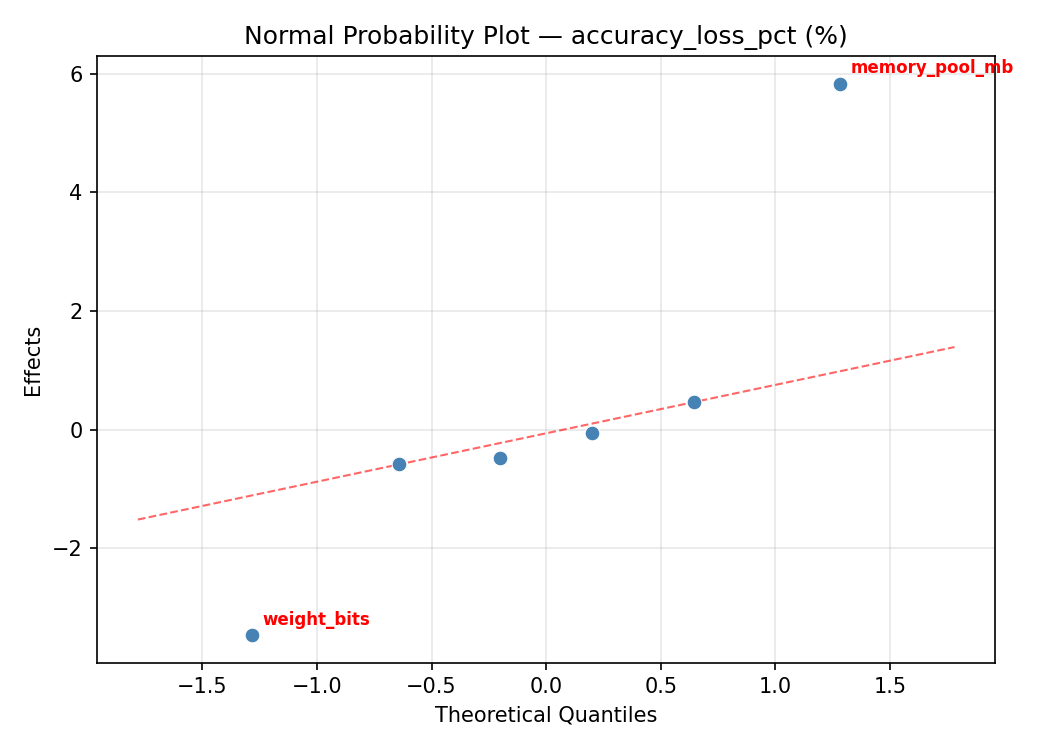
Normal Probability Plot of Effects
Half-Normal Plot of Effects
Model Diagnostics
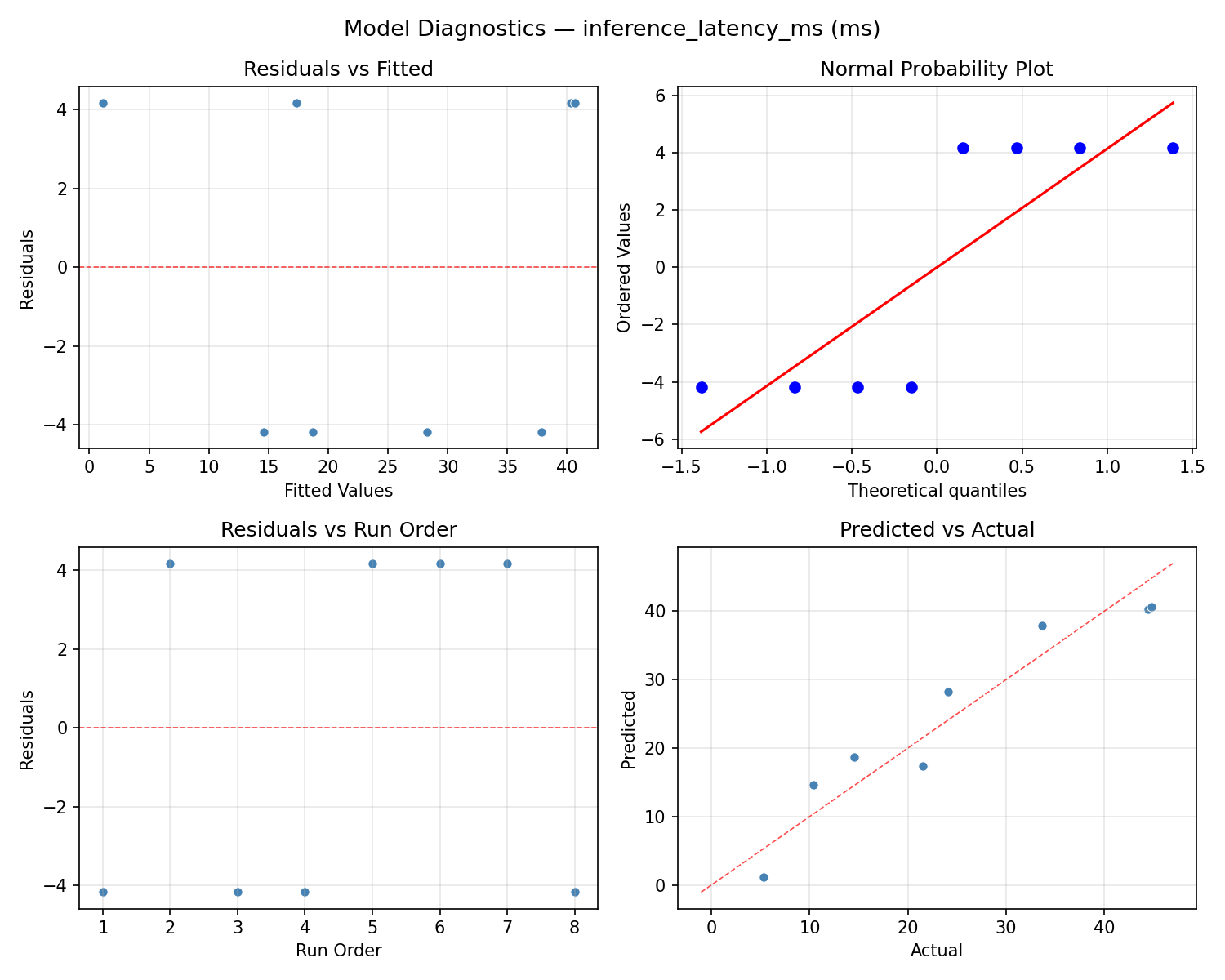
Response: accuracy_loss_pct
Top factors: memory_pool_mb (49.1%), weight_bits (32.3%), cache_size_kb (9.7%).
ANOVA
| Source | DF | SS | MS | F | p-value |
|---|
| Source | DF | SS | MS | F | p-value |
| weight_bits | 1 | 29.3761 | 29.3761 | 41.289 | 0.0004 |
| activation_bits | 1 | 0.0435 | 0.0435 | 0.061 | 0.8118 |
| batch_size | 1 | 0.8001 | 0.8001 | 1.125 | 0.3241 |
| num_threads | 1 | 0.1485 | 0.1485 | 0.209 | 0.6616 |
| cache_size_kb | 1 | 2.6796 | 2.6796 | 3.766 | 0.0934 |
| memory_pool_mb | 1 | 68.0361 | 68.0361 | 95.628 | 0.0000 |
| weight_bits*activation_bits | 1 | 0.8001 | 0.8001 | 1.125 | 0.3241 |
| weight_bits*batch_size | 1 | 0.0435 | 0.0435 | 0.061 | 0.8118 |
| weight_bits*num_threads | 1 | 2.6796 | 2.6796 | 3.766 | 0.0934 |
| weight_bits*cache_size_kb | 1 | 0.1485 | 0.1485 | 0.209 | 0.6616 |
| weight_bits*memory_pool_mb | 1 | 47.6776 | 47.6776 | 67.013 | 0.0001 |
| activation_bits*batch_size | 1 | 29.3761 | 29.3761 | 41.289 | 0.0004 |
| activation_bits*num_threads | 1 | 68.0361 | 68.0361 | 95.628 | 0.0000 |
| activation_bits*cache_size_kb | 1 | 47.6776 | 47.6776 | 67.013 | 0.0001 |
| activation_bits*memory_pool_mb | 1 | 0.1485 | 0.1485 | 0.209 | 0.6616 |
| batch_size*num_threads | 1 | 47.6776 | 47.6776 | 67.013 | 0.0001 |
| batch_size*cache_size_kb | 1 | 68.0361 | 68.0361 | 95.628 | 0.0000 |
| batch_size*memory_pool_mb | 1 | 2.6796 | 2.6796 | 3.766 | 0.0934 |
| num_threads*cache_size_kb | 1 | 29.3761 | 29.3761 | 41.289 | 0.0004 |
| num_threads*memory_pool_mb | 1 | 0.0435 | 0.0435 | 0.061 | 0.8118 |
| cache_size_kb*memory_pool_mb | 1 | 0.8001 | 0.8001 | 1.125 | 0.3241 |
| Error | (Lenth | PSE) | 7 | 4.9803 | 0.7115 |
| Total | 7 | 148.7616 | 21.2517 | | |
Pareto Chart
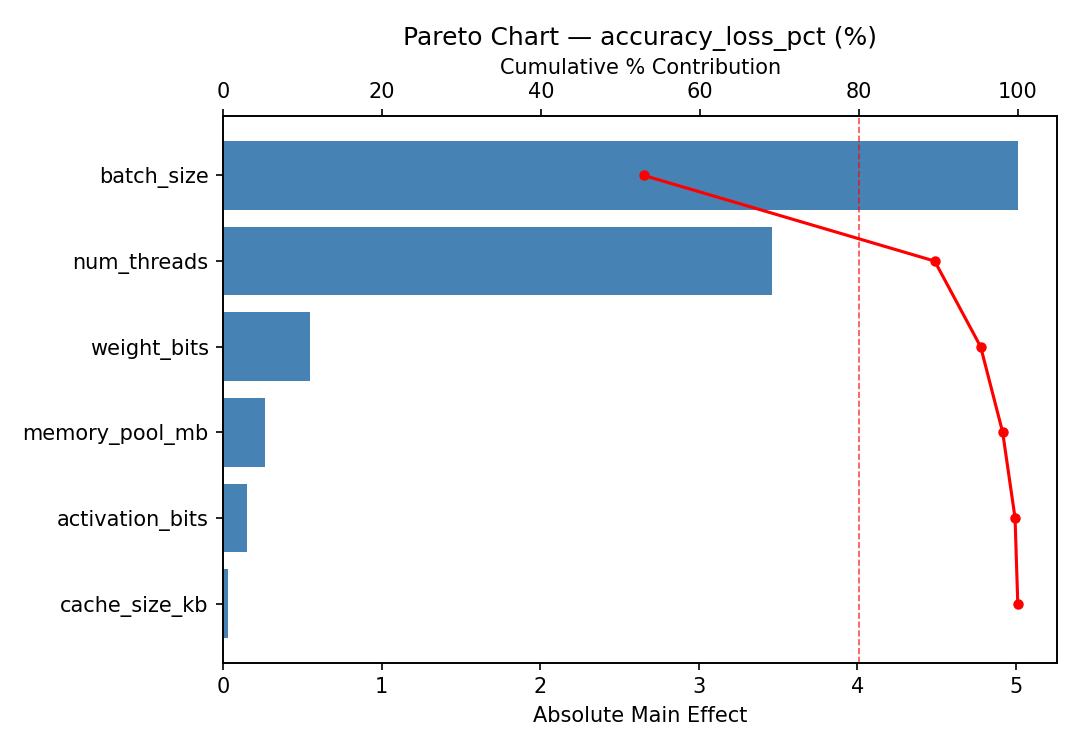
Main Effects Plot
Normal Probability Plot of Effects
Half-Normal Plot of Effects
Model Diagnostics
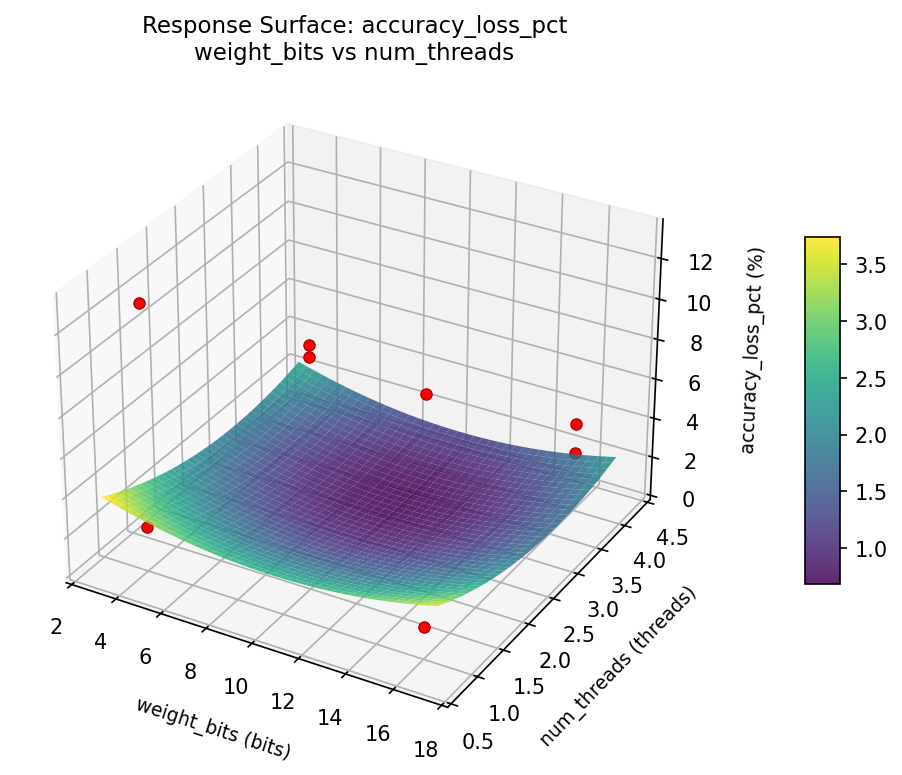
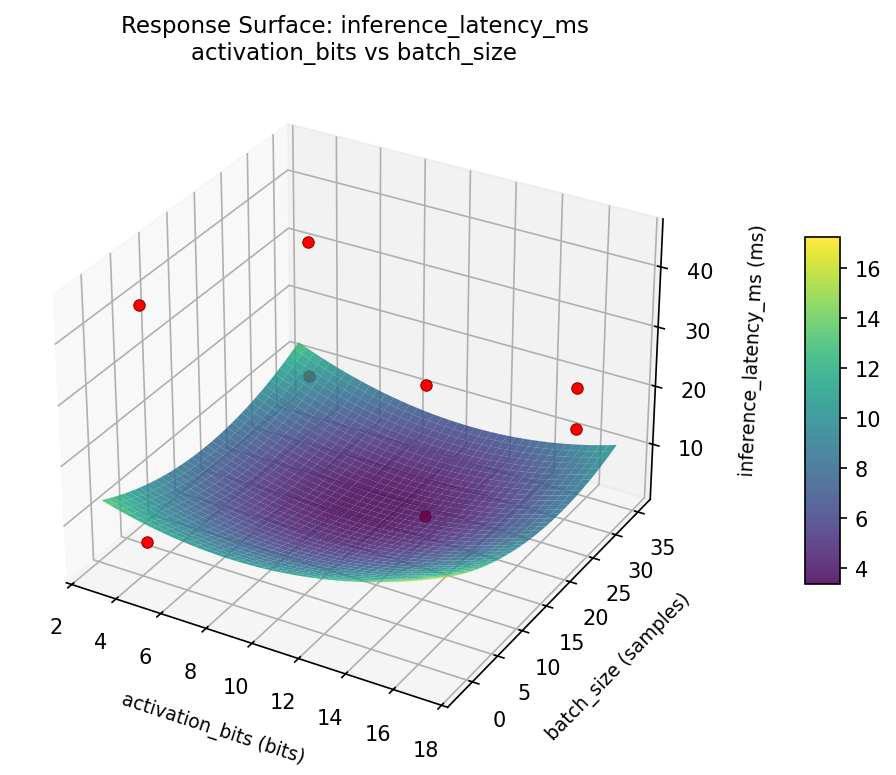
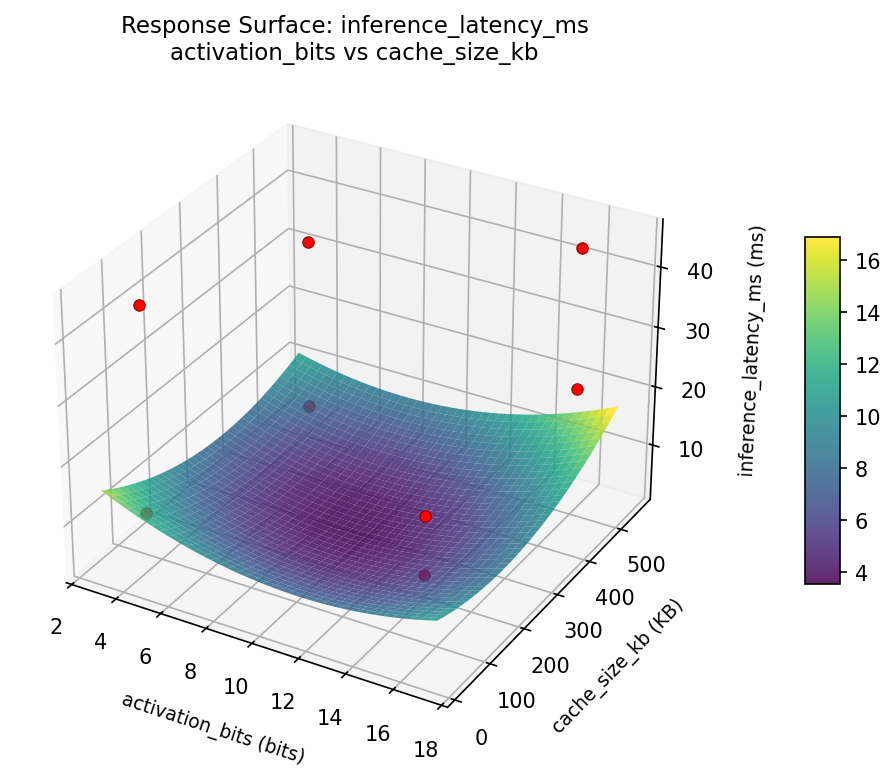
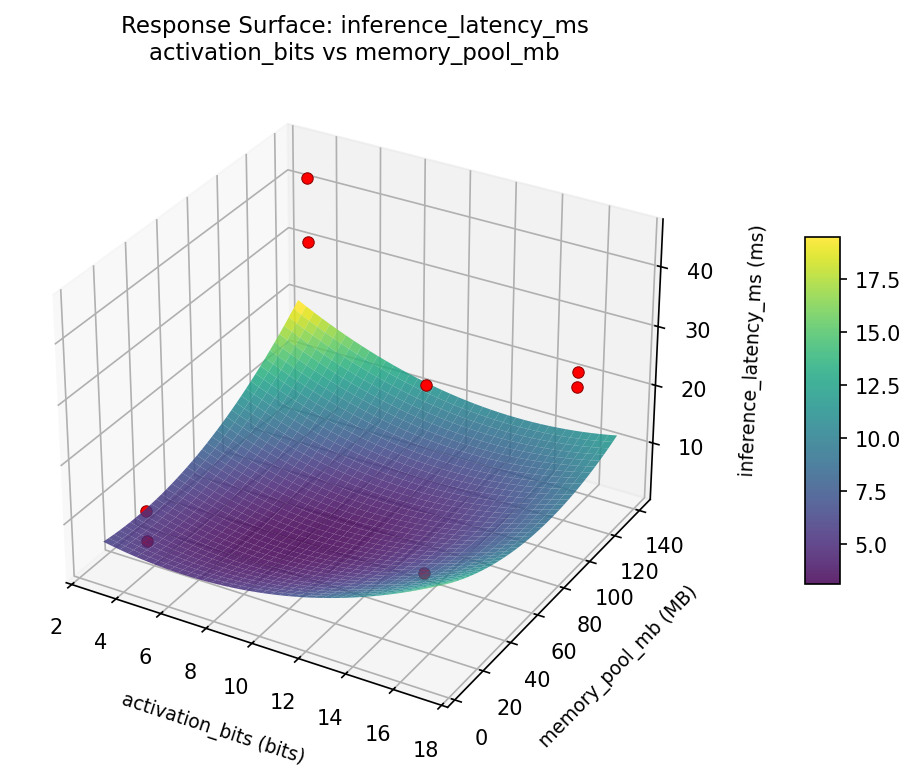
Response Surface Plots
3D surfaces fitted with quadratic RSM. Red dots are observed data points.
accuracy loss pct activation bits vs batch size
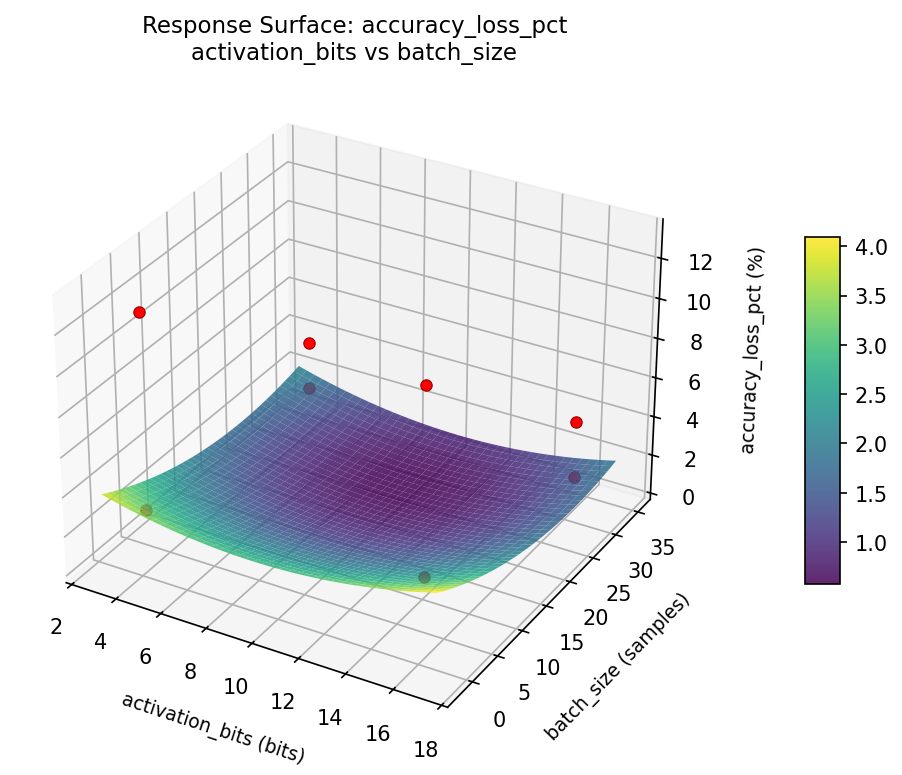
accuracy loss pct activation bits vs cache size kb
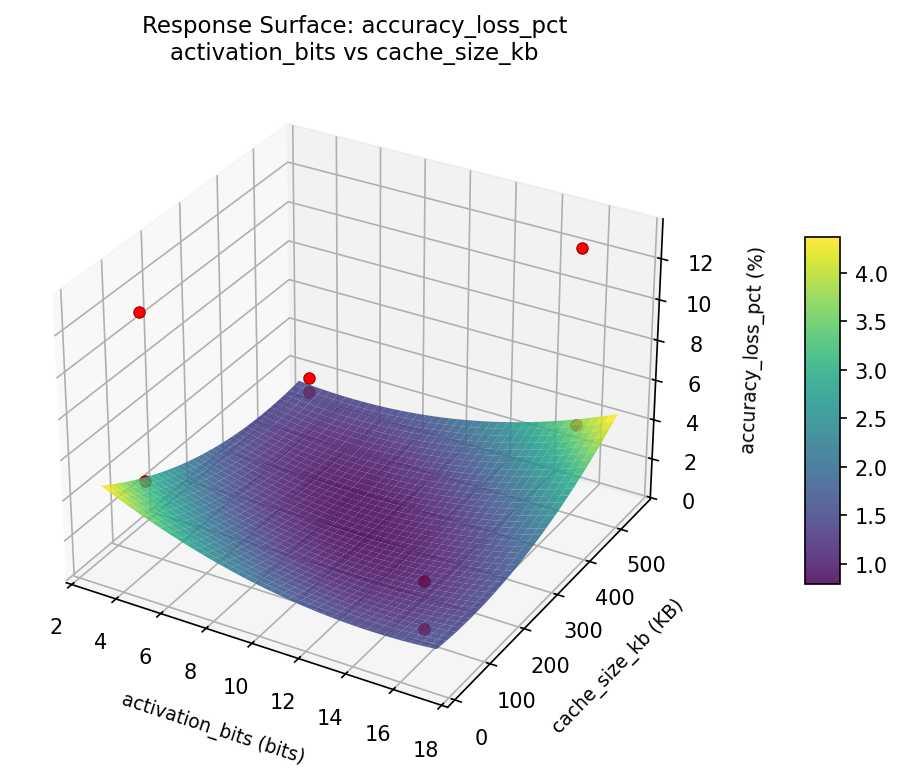
accuracy loss pct activation bits vs memory pool mb
accuracy loss pct activation bits vs num threads
accuracy loss pct batch size vs cache size kb
accuracy loss pct batch size vs memory pool mb
accuracy loss pct batch size vs num threads
accuracy loss pct cache size kb vs memory pool mb
accuracy loss pct num threads vs cache size kb
accuracy loss pct num threads vs memory pool mb
accuracy loss pct weight bits vs activation bits
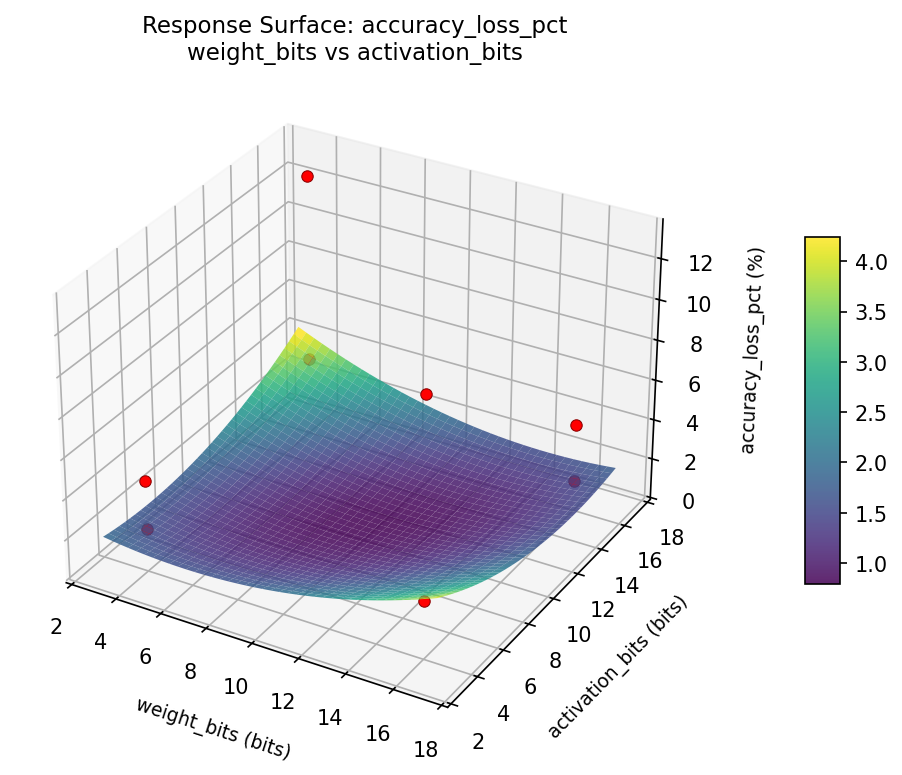
accuracy loss pct weight bits vs batch size
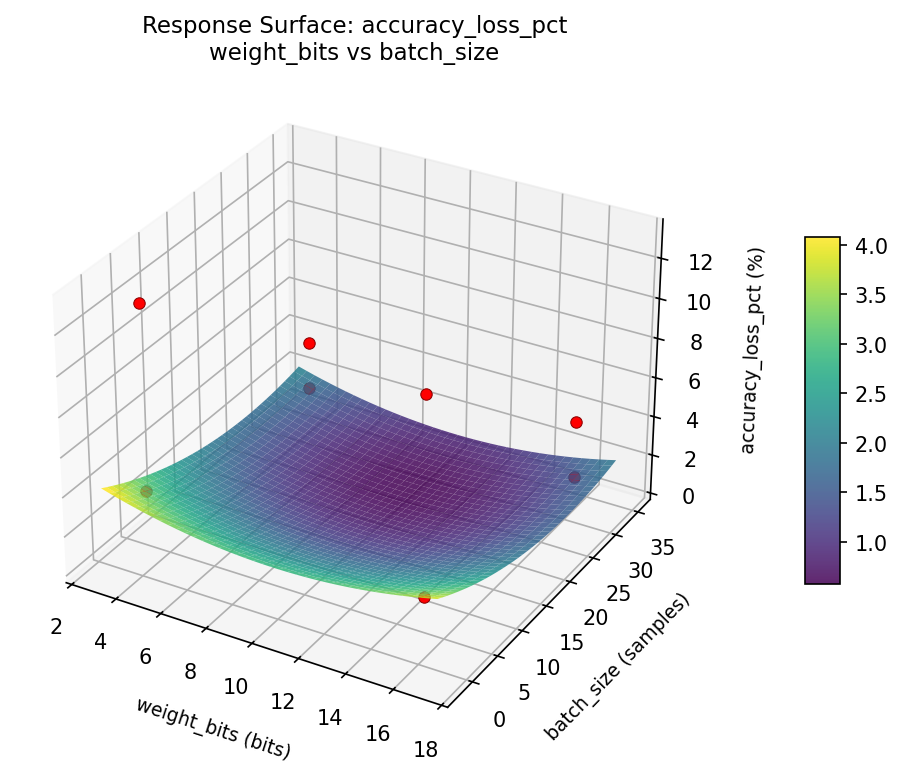
accuracy loss pct weight bits vs cache size kb
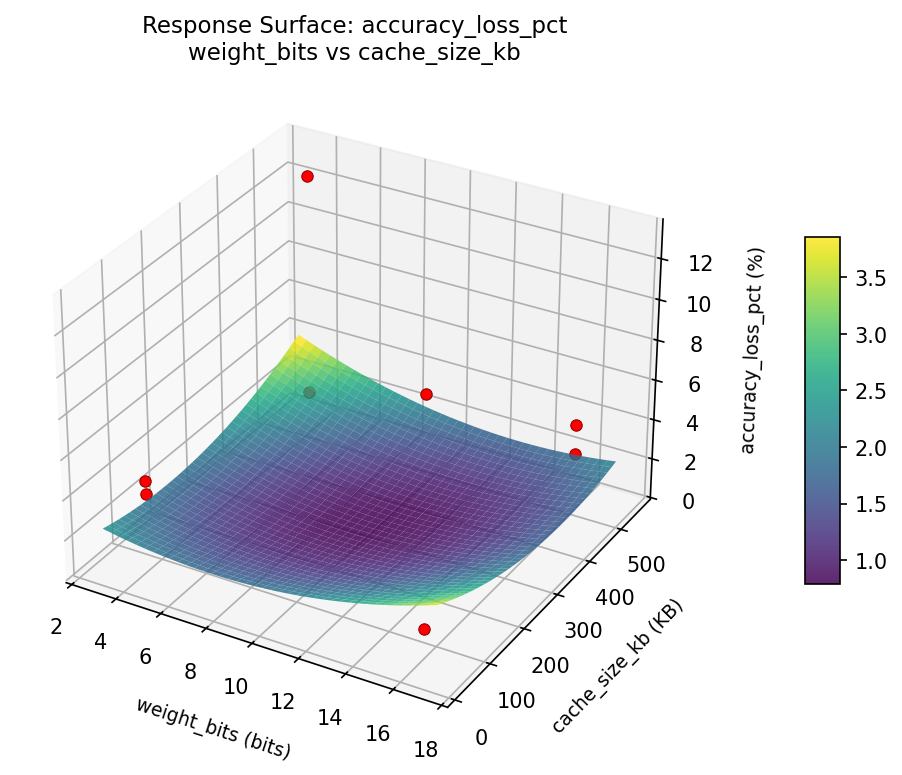
accuracy loss pct weight bits vs memory pool mb
accuracy loss pct weight bits vs num threads
inference latency ms activation bits vs batch size
inference latency ms activation bits vs cache size kb
inference latency ms activation bits vs memory pool mb
inference latency ms activation bits vs num threads
inference latency ms batch size vs cache size kb
inference latency ms batch size vs memory pool mb
inference latency ms batch size vs num threads
inference latency ms cache size kb vs memory pool mb
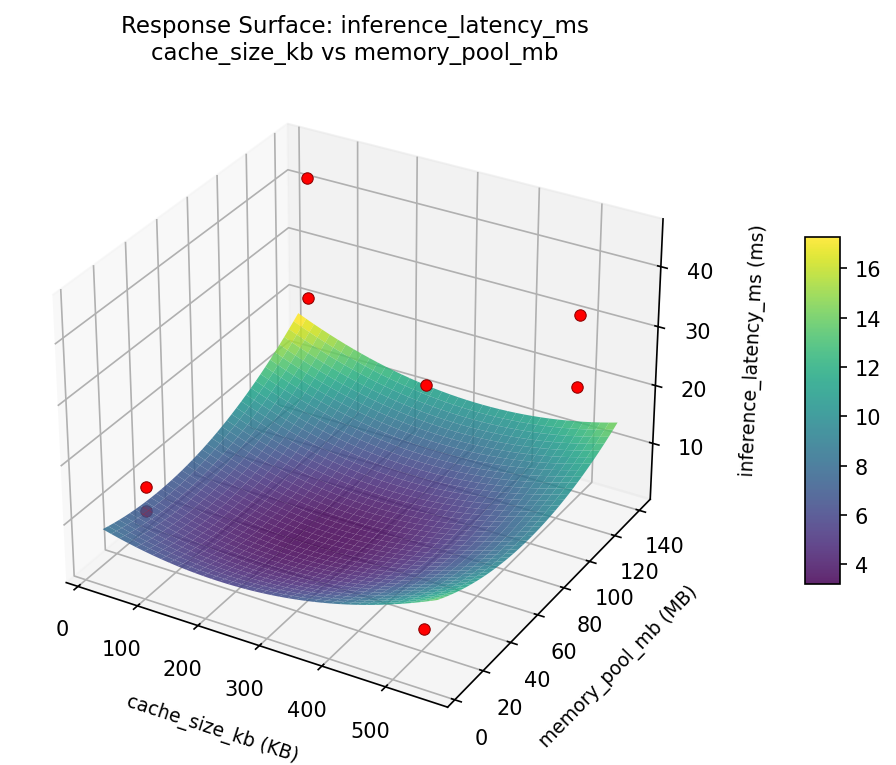
inference latency ms num threads vs cache size kb
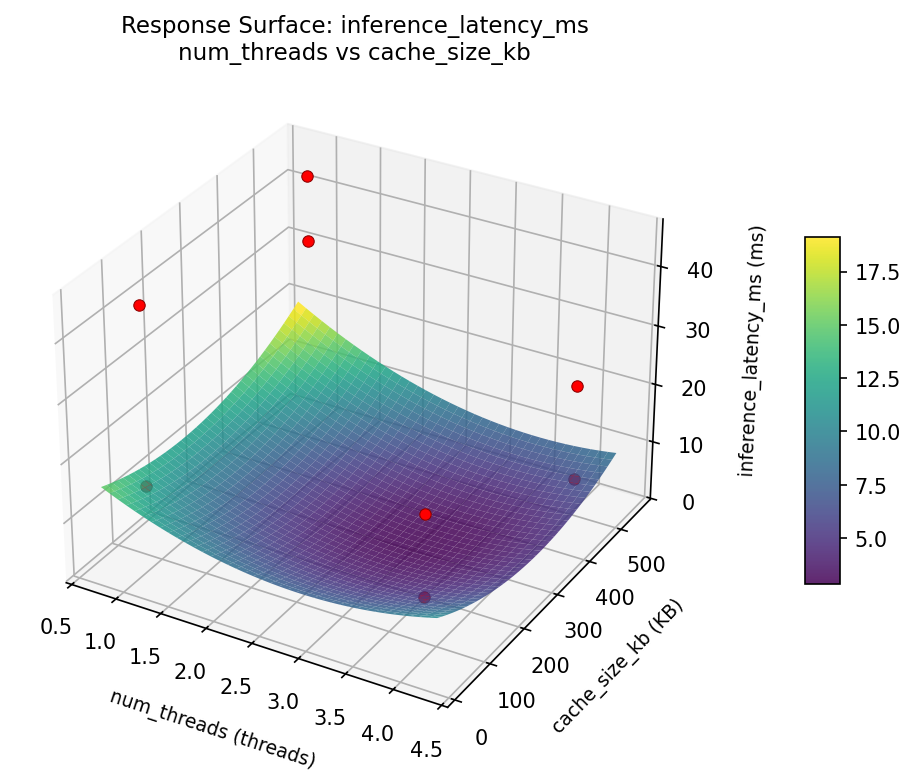
inference latency ms num threads vs memory pool mb
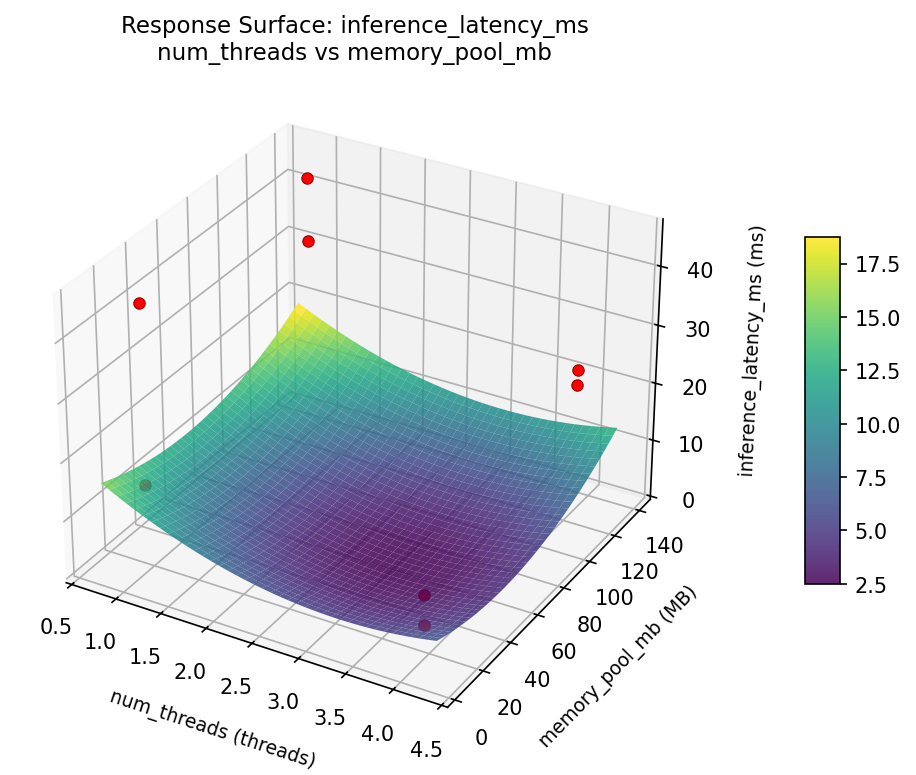
inference latency ms weight bits vs activation bits
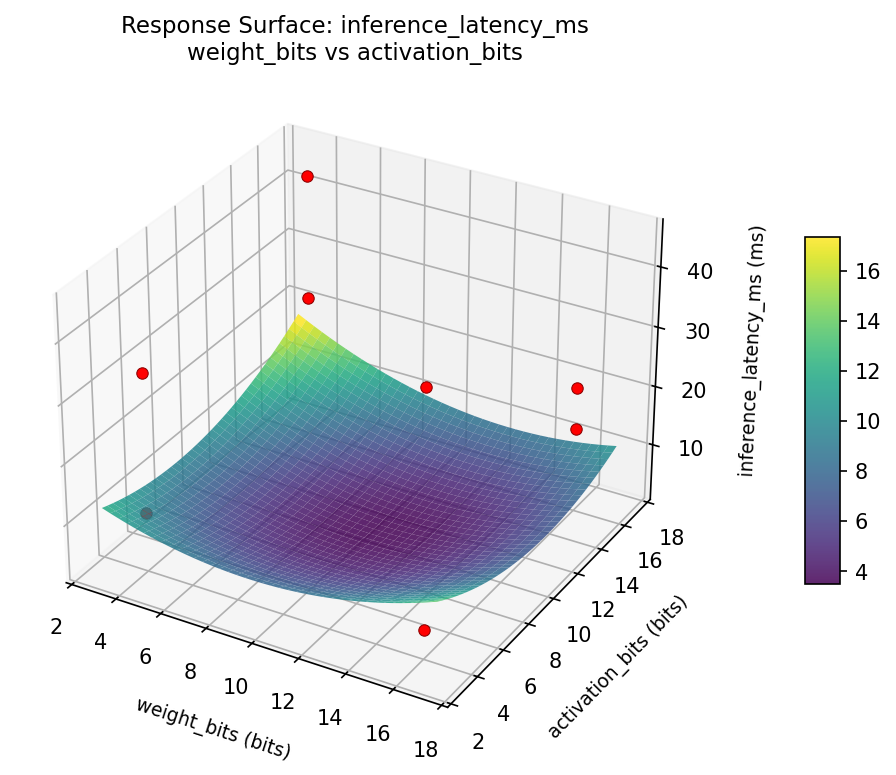
inference latency ms weight bits vs batch size
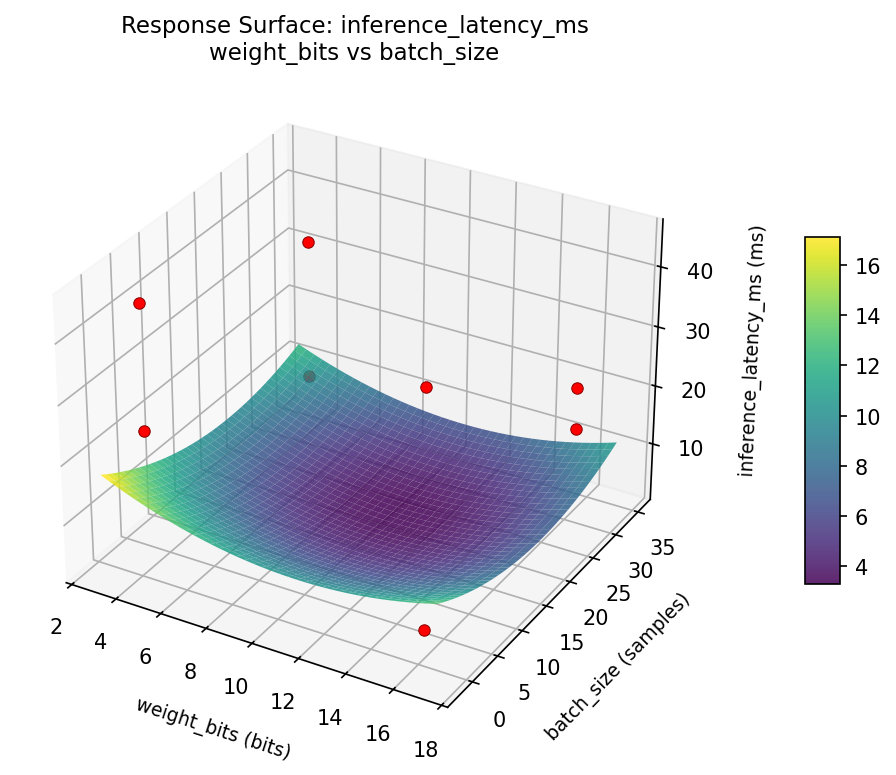
inference latency ms weight bits vs cache size kb
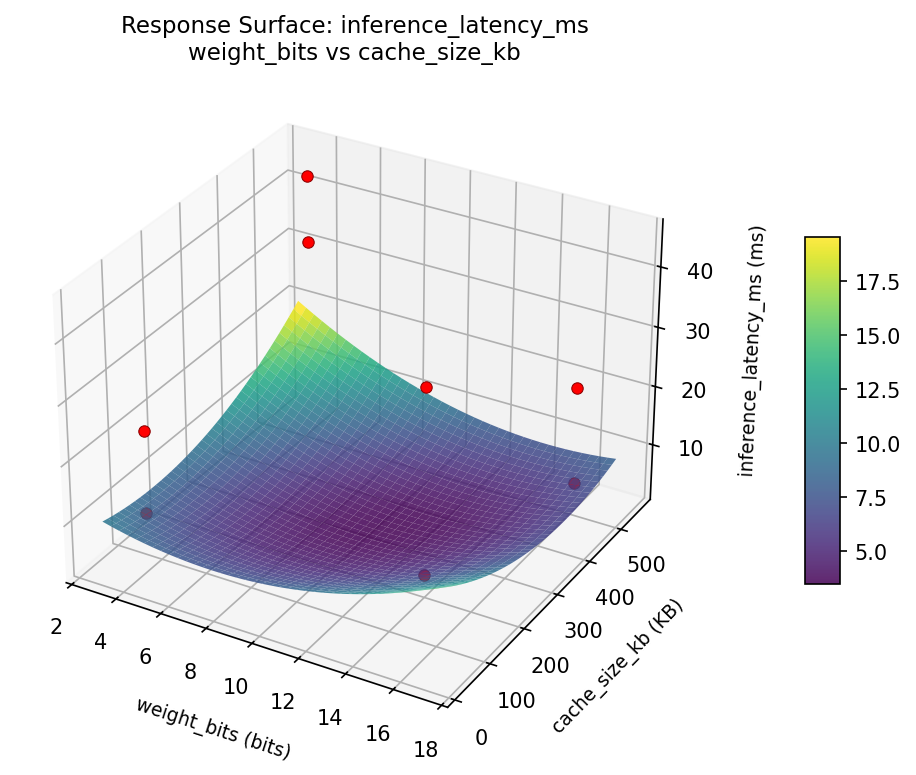
inference latency ms weight bits vs memory pool mb
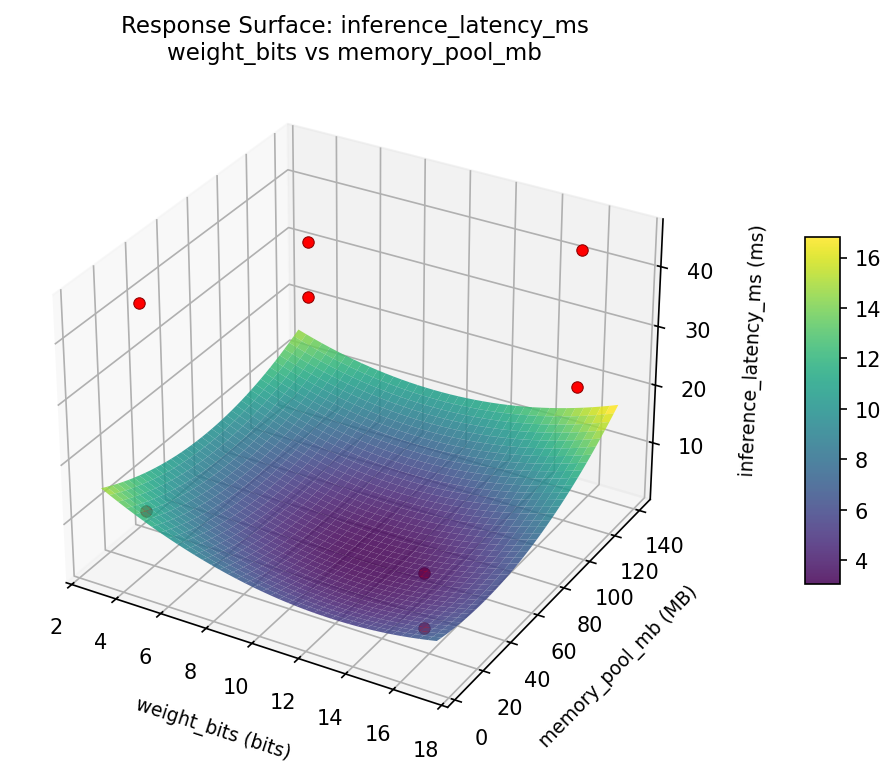
inference latency ms weight bits vs num threads
Multi-Objective Optimization
When responses compete, Derringer–Suich desirability finds the best compromise.
Each response is scaled to a 0–1 desirability, then combined via a weighted geometric mean.
Overall Desirability
D = 1.0000
Per-Response Desirability
| Response | Weight | Desirability | Predicted | Dir |
|---|
inference_latency_ms |
1.0 |
|
2.29 1.0000 2.29 ms |
↓ |
accuracy_loss_pct |
1.5 |
|
-0.38 1.0000 -0.38 % |
↓ |
Recommended Settings
| Factor | Value |
|---|
weight_bits | 5.363 bits |
activation_bits | 14.97 bits |
batch_size | 5.221 samples |
num_threads | 3.976 threads |
cache_size_kb | 310.7 KB |
memory_pool_mb | 19.78 MB |
Source: from RSM model prediction
Trade-off Summary
Sacrifice = how much worse than single-objective best.
| Response | Predicted | Best Observed | Sacrifice |
|---|
accuracy_loss_pct | -0.38 | 1.42 | -1.80 |
Top 3 Runs by Desirability
| Run | D | Factor Settings |
|---|
| #4 | 0.8634 | weight_bits=16, activation_bits=16, batch_size=32, num_threads=4, cache_size_kb=512, memory_pool_mb=128 |
| #3 | 0.7639 | weight_bits=16, activation_bits=4, batch_size=1, num_threads=4, cache_size_kb=512, memory_pool_mb=16 |
Model Quality
| Response | R² | Type |
|---|
accuracy_loss_pct | 0.9997 | linear |
Full Multi-Objective Output
============================================================
MULTI-OBJECTIVE OPTIMIZATION
Method: Derringer-Suich Desirability Function
============================================================
Overall desirability: D = 1.0000
Response Weight Desirability Predicted Direction
---------------------------------------------------------------------
inference_latency_ms 1.0 1.0000 2.29 ms ↓
accuracy_loss_pct 1.5 1.0000 -0.38 % ↓
Recommended settings:
weight_bits = 5.363 bits
activation_bits = 14.97 bits
batch_size = 5.221 samples
num_threads = 3.976 threads
cache_size_kb = 310.7 KB
memory_pool_mb = 19.78 MB
(from RSM model prediction)
Trade-off summary:
inference_latency_ms: 2.29 (best observed: 5.30, sacrifice: -3.01)
accuracy_loss_pct: -0.38 (best observed: 1.42, sacrifice: -1.80)
Model quality:
inference_latency_ms: R² = 0.9904 (linear)
accuracy_loss_pct: R² = 0.9997 (linear)
Top 3 observed runs by overall desirability:
1. Run #6 (D=0.8886): weight_bits=4, activation_bits=16, batch_size=1, num_threads=4, cache_size_kb=64, memory_pool_mb=128
2. Run #4 (D=0.8634): weight_bits=16, activation_bits=16, batch_size=32, num_threads=4, cache_size_kb=512, memory_pool_mb=128
3. Run #3 (D=0.7639): weight_bits=16, activation_bits=4, batch_size=1, num_threads=4, cache_size_kb=512, memory_pool_mb=16
Full Analysis Output
=== Main Effects: inference_latency_ms ===
Factor Effect Std Error % Contribution
--------------------------------------------------------------
memory_pool_mb -12.2000 5.2989 35.1%
cache_size_kb 8.7000 5.2989 25.0%
weight_bits 4.8500 5.2989 14.0%
num_threads -4.2500 5.2989 12.2%
activation_bits 2.7500 5.2989 7.9%
batch_size 2.0000 5.2989 5.8%
=== ANOVA Table: inference_latency_ms ===
Source DF SS MS F p-value
-----------------------------------------------------------------------------
weight_bits 1 47.0450 47.0450 0.868 0.3825
activation_bits 1 15.1250 15.1250 0.279 0.6136
batch_size 1 8.0000 8.0000 0.148 0.7122
num_threads 1 36.1250 36.1250 0.667 0.4411
cache_size_kb 1 151.3800 151.3800 2.794 0.1386
memory_pool_mb 1 297.6800 297.6800 5.494 0.0516
weight_bits*activation_bits 1 8.0000 8.0000 0.148 0.7122
weight_bits*batch_size 1 15.1250 15.1250 0.279 0.6136
weight_bits*num_threads 1 151.3800 151.3800 2.794 0.1386
weight_bits*cache_size_kb 1 36.1250 36.1250 0.667 0.4411
weight_bits*memory_pool_mb 1 1017.0050 1017.0050 18.768 0.0034
activation_bits*batch_size 1 47.0450 47.0450 0.868 0.3825
activation_bits*num_threads 1 297.6800 297.6800 5.494 0.0516
activation_bits*cache_size_kb 1 1017.0050 1017.0050 18.768 0.0034
activation_bits*memory_pool_mb 1 36.1250 36.1250 0.667 0.4411
batch_size*num_threads 1 1017.0050 1017.0050 18.768 0.0034
batch_size*cache_size_kb 1 297.6800 297.6800 5.494 0.0516
batch_size*memory_pool_mb 1 151.3800 151.3800 2.794 0.1386
num_threads*cache_size_kb 1 47.0450 47.0450 0.868 0.3825
num_threads*memory_pool_mb 1 15.1250 15.1250 0.279 0.6136
cache_size_kb*memory_pool_mb 1 8.0000 8.0000 0.148 0.7122
Error (Lenth PSE) 7 379.3125 54.1875
Total 7 1572.3600 224.6229
Note: Error estimated using Lenth's pseudo-standard-error (unreplicated design)
=== Interaction Effects: inference_latency_ms ===
Factor A Factor B Interaction % Contribution
------------------------------------------------------------------------
weight_bits memory_pool_mb -22.5500 16.4%
activation_bits cache_size_kb -22.5500 16.4%
batch_size num_threads -22.5500 16.4%
activation_bits num_threads -12.2000 8.9%
batch_size cache_size_kb -12.2000 8.9%
weight_bits num_threads 8.7000 6.3%
batch_size memory_pool_mb 8.7000 6.3%
activation_bits batch_size 4.8500 3.5%
num_threads cache_size_kb 4.8500 3.5%
weight_bits cache_size_kb -4.2500 3.1%
activation_bits memory_pool_mb -4.2500 3.1%
weight_bits batch_size 2.7500 2.0%
num_threads memory_pool_mb 2.7500 2.0%
weight_bits activation_bits 2.0000 1.5%
cache_size_kb memory_pool_mb 2.0000 1.5%
=== Summary Statistics: inference_latency_ms ===
weight_bits:
Level N Mean Std Min Max
------------------------------------------------------------
16 4 22.4250 9.5810 10.4000 33.7000
4 4 27.2750 20.4118 5.3000 44.8000
activation_bits:
Level N Mean Std Min Max
------------------------------------------------------------
16 4 23.4750 18.6895 5.3000 44.5000
4 4 26.2250 13.0301 14.5000 44.8000
batch_size:
Level N Mean Std Min Max
------------------------------------------------------------
1 4 23.8500 16.0843 5.3000 44.5000
32 4 25.8500 16.2096 10.4000 44.8000
num_threads:
Level N Mean Std Min Max
------------------------------------------------------------
1 4 26.9750 16.7434 5.3000 44.8000
4 4 22.7250 15.2229 10.4000 44.5000
cache_size_kb:
Level N Mean Std Min Max
------------------------------------------------------------
512 4 20.5000 17.5551 5.3000 44.8000
64 4 29.2000 12.8639 14.5000 44.5000
memory_pool_mb:
Level N Mean Std Min Max
------------------------------------------------------------
128 4 30.9500 16.7795 10.4000 44.8000
16 4 18.7500 11.9726 5.3000 33.7000
=== Main Effects: accuracy_loss_pct ===
Factor Effect Std Error % Contribution
--------------------------------------------------------------
memory_pool_mb -5.8325 1.6299 49.1%
weight_bits 3.8325 1.6299 32.3%
cache_size_kb -1.1575 1.6299 9.7%
batch_size -0.6325 1.6299 5.3%
num_threads 0.2725 1.6299 2.3%
activation_bits 0.1475 1.6299 1.2%
=== ANOVA Table: accuracy_loss_pct ===
Source DF SS MS F p-value
-----------------------------------------------------------------------------
weight_bits 1 29.3761 29.3761 41.289 0.0004
activation_bits 1 0.0435 0.0435 0.061 0.8118
batch_size 1 0.8001 0.8001 1.125 0.3241
num_threads 1 0.1485 0.1485 0.209 0.6616
cache_size_kb 1 2.6796 2.6796 3.766 0.0934
memory_pool_mb 1 68.0361 68.0361 95.628 0.0000
weight_bits*activation_bits 1 0.8001 0.8001 1.125 0.3241
weight_bits*batch_size 1 0.0435 0.0435 0.061 0.8118
weight_bits*num_threads 1 2.6796 2.6796 3.766 0.0934
weight_bits*cache_size_kb 1 0.1485 0.1485 0.209 0.6616
weight_bits*memory_pool_mb 1 47.6776 47.6776 67.013 0.0001
activation_bits*batch_size 1 29.3761 29.3761 41.289 0.0004
activation_bits*num_threads 1 68.0361 68.0361 95.628 0.0000
activation_bits*cache_size_kb 1 47.6776 47.6776 67.013 0.0001
activation_bits*memory_pool_mb 1 0.1485 0.1485 0.209 0.6616
batch_size*num_threads 1 47.6776 47.6776 67.013 0.0001
batch_size*cache_size_kb 1 68.0361 68.0361 95.628 0.0000
batch_size*memory_pool_mb 1 2.6796 2.6796 3.766 0.0934
num_threads*cache_size_kb 1 29.3761 29.3761 41.289 0.0004
num_threads*memory_pool_mb 1 0.0435 0.0435 0.061 0.8118
cache_size_kb*memory_pool_mb 1 0.8001 0.8001 1.125 0.3241
Error (Lenth PSE) 7 4.9803 0.7115
Total 7 148.7616 21.2517
Note: Error estimated using Lenth's pseudo-standard-error (unreplicated design)
=== Interaction Effects: accuracy_loss_pct ===
Factor A Factor B Interaction % Contribution
------------------------------------------------------------------------
activation_bits num_threads -5.8325 15.2%
batch_size cache_size_kb -5.8325 15.2%
weight_bits memory_pool_mb -4.8825 12.7%
activation_bits cache_size_kb -4.8825 12.7%
batch_size num_threads -4.8825 12.7%
activation_bits batch_size 3.8325 10.0%
num_threads cache_size_kb 3.8325 10.0%
weight_bits num_threads -1.1575 3.0%
batch_size memory_pool_mb -1.1575 3.0%
weight_bits activation_bits -0.6325 1.6%
cache_size_kb memory_pool_mb -0.6325 1.6%
weight_bits cache_size_kb 0.2725 0.7%
activation_bits memory_pool_mb 0.2725 0.7%
weight_bits batch_size 0.1475 0.4%
num_threads memory_pool_mb 0.1475 0.4%
=== Summary Statistics: accuracy_loss_pct ===
weight_bits:
Level N Mean Std Min Max
------------------------------------------------------------
16 4 3.6300 1.0887 2.0500 4.4300
4 4 7.4625 6.2137 1.4200 13.0200
activation_bits:
Level N Mean Std Min Max
------------------------------------------------------------
16 4 5.4725 4.8677 2.0500 12.6200
4 4 5.6200 5.0871 1.4200 13.0200
batch_size:
Level N Mean Std Min Max
------------------------------------------------------------
1 4 5.8625 4.5464 2.7900 12.6200
32 4 5.2300 5.3527 1.4200 13.0200
num_threads:
Level N Mean Std Min Max
------------------------------------------------------------
1 4 5.4100 5.1226 2.0500 13.0200
4 4 5.6825 4.8267 1.4200 12.6200
cache_size_kb:
Level N Mean Std Min Max
------------------------------------------------------------
512 4 6.1250 4.6553 2.7900 13.0200
64 4 4.9675 5.1983 1.4200 12.6200
memory_pool_mb:
Level N Mean Std Min Max
------------------------------------------------------------
128 4 8.4625 5.0412 3.7800 13.0200
16 4 2.6300 1.2224 1.4200 4.2600
Optimization Recommendations
=== Optimization: inference_latency_ms ===
Direction: minimize
Best observed run: #6
weight_bits = 16
activation_bits = 4
batch_size = 1
num_threads = 1
cache_size_kb = 64
memory_pool_mb = 128
Value: 5.3
RSM Model (linear, R² = 0.8107, Adj R² = -0.3252):
Coefficients:
intercept +24.8500
weight_bits -0.9250
activation_bits -7.2250
batch_size +6.1000
num_threads +2.7500
cache_size_kb +6.4750
memory_pool_mb -4.4250
Predicted optimum (from linear model, at observed points):
weight_bits = 4
activation_bits = 4
batch_size = 32
num_threads = 4
cache_size_kb = 64
memory_pool_mb = 16
Predicted value: 39.8000
Surface optimum (via L-BFGS-B, linear model):
weight_bits = 16
activation_bits = 16
batch_size = 1
num_threads = 1
cache_size_kb = 64
memory_pool_mb = 128
Predicted value: -3.0500
Model quality: Good fit — general trends are captured, some noise remains.
Factor importance:
1. activation_bits (effect: 14.5, contribution: 25.9%)
2. cache_size_kb (effect: -12.9, contribution: 23.2%)
3. batch_size (effect: 12.2, contribution: 21.9%)
4. memory_pool_mb (effect: 8.8, contribution: 15.9%)
5. num_threads (effect: 5.5, contribution: 9.9%)
6. weight_bits (effect: 1.9, contribution: 3.3%)
=== Optimization: accuracy_loss_pct ===
Direction: minimize
Best observed run: #4
weight_bits = 4
activation_bits = 16
batch_size = 1
num_threads = 1
cache_size_kb = 512
memory_pool_mb = 16
Value: 1.42
RSM Model (linear, R² = 0.5426, Adj R² = -2.2015):
Coefficients:
intercept +5.5462
weight_bits +0.4163
activation_bits -2.0737
batch_size +0.1312
num_threads +0.3937
cache_size_kb +2.2838
memory_pool_mb +0.4787
Predicted optimum (from linear model, at observed points):
weight_bits = 16
activation_bits = 4
batch_size = 1
num_threads = 4
cache_size_kb = 512
memory_pool_mb = 16
Predicted value: 10.1038
Surface optimum (via L-BFGS-B, linear model):
weight_bits = 4
activation_bits = 16
batch_size = 1
num_threads = 1
cache_size_kb = 64
memory_pool_mb = 16
Predicted value: -0.2313
Model quality: Moderate fit — use predictions directionally, not precisely.
Factor importance:
1. cache_size_kb (effect: -4.6, contribution: 39.5%)
2. activation_bits (effect: 4.1, contribution: 35.9%)
3. memory_pool_mb (effect: -1.0, contribution: 8.3%)
4. weight_bits (effect: -0.8, contribution: 7.2%)
5. num_threads (effect: 0.8, contribution: 6.8%)
6. batch_size (effect: 0.3, contribution: 2.3%)